\(\newcommand{\bfbeta}{\boldsymbol{\beta}}\) \(\newcommand{\bflambda}{\boldsymbol{\lambda}}\)
2.7. Online supplementary materials#
2.7.1. Quizzes, solutions, code, etc.#
2.7.1.1. Just the code#
An interactive Jupyter notebook featuring the code in this chapter can be accessed below (Google Colab recommended). You are encouraged to tinker with it. Some suggested computational exercises are scattered throughout. The notebook is also available as a slideshow.
2.7.1.2. Self-assessment quizzes#
A more extensive web version of the self-assessment quizzes is available by following the links below.
2.7.1.3. Auto-quizzes#
Automatically generated quizzes for this chapter can be accessed here (Google Colab recommended).
2.7.1.4. Solutions to odd-numbered warm-up exercises#
(with help from Claude, Gemini, and ChatGPT)
Answer and justification for E2.2.1: Yes, \(U\) is a linear subspace of \(\mathbb{R}^3\). Let \(u_1 = (x_1, y_1, z_1), u_2 = (x_2, y_2, z_2) \in U\) and \(\alpha \in \mathbb{R}\). Then
So \(\alpha u_1 + u_2 \in U\), proving \(U\) is a linear subspace.
Answer and justification for E2.2.3: One basis for \(U\) is \(\{(1, 1, 0), (-1, 0, 1)\}\). Any vector \((x, y, z) \in U\) can be written as
So \(\{(1, 1, 0), (-1, 0, 1)\}\) spans \(U\). They are also linearly independent, as \(\alpha(1, 1, 0) + \beta(-1, 0, 1) = \mathbf{0}\) implies \(\alpha = \beta = 0\). Thus, this is a basis for \(U\).
Answer and justification for E2.2.5: Yes, \(u_1\) and \(u_2\) form an orthonormal list. We have
So \(u_1\) and \(u_2\) are unit vectors and are orthogonal to each other.
Answer and justification for E2.2.7: \(A\) is nonsingular. Its columns are \((1, 3)\) and \((2, 4)\), which are linearly independent
This system has only the trivial solution \(\alpha = \beta = 0\). So the columns of \(A\) are linearly independent, and since \(A\) is a \(2 \times 2\) matrix, this means it has rank 2 and is nonsingular.
Answer and justification for E2.2.9:
Solving the system of equations
Substitute \(\alpha = 2\) and \(\beta = 3\) into the third equation
Thus, \(\mathbf{v} = 2\mathbf{w}_1 + 3\mathbf{w}_2\).
Answer and justification for E2.2.11: To find the null space, we need to solve the homogeneous system \(B\mathbf{x} = \mathbf{0}\):
This gives us two equations with three unknowns:
Multiplying equation (1) by 4:
Subtracting equation (3) from equation (2):
This simplifies to:
Dividing by -3: $\( x_2 = -2x_3 \)$
Now, substituting this back into equation (1):
Therefore:
Setting \(x_3 = t\) (a free parameter), we get:
The null space of \(B\) is the span of the vector \(\begin{pmatrix} 1 \\ -2 \\ 1 \end{pmatrix}\).
Answer and justification for E2.2.13: To determine linear independence, we need to check if the only solution to \(\alpha_1\mathbf{u}_1 + \alpha_2\mathbf{u}_2 + \alpha_3\mathbf{u}_3 = \mathbf{0}\) is \(\alpha_1 = \alpha_2 = \alpha_3 = 0\).
Let’s write out this vector equation:
This gives us a system of three equations:
From equation (3):
Which gives us:
Substituting this into equation (1):
Now let’s check equation (2) by substituting equations (4) and (5):
Simplifying:
Since \(\frac{7\alpha_3}{2} = 0\) implies \(\alpha_3 = 0\), and from equations (4) and (5), we get \(\alpha_1 = 0\) and \(\alpha_2 = 0\).
Therefore, the only solution to the system is the trivial solution \(\alpha_1 = \alpha_2 = \alpha_3 = 0\), which means the vectors \(\mathbf{u}_1\), \(\mathbf{u}_2\), and \(\mathbf{u}_3\) are linearly independent.
Consider the equation \(\alpha_1\mathbf{u}_1 + \alpha_2\mathbf{u}_2 + \alpha_3\mathbf{u}_3 = 0\). This leads to the system of equations
Solving this system, we find that \(\alpha_1 = -2\alpha_3\) and \(\alpha_2 = \alpha_3\). Choosing \(\alpha_3 = 1\), we get a non-trivial solution \(\alpha_1 = -2\), \(\alpha_2 = 1\), \(\alpha_3 = 1\). Therefore, the vectors are linearly dependent.
Answer and justification for E2.2.15: We can write this system as \(A\mathbf{x} = \mathbf{b}\), where \(A = \begin{bmatrix} 2 & 1 \\ 1 & -1 \end{bmatrix}\), \(\mathbf{x} = \begin{bmatrix} x \\ y \end{bmatrix}\), and \(\mathbf{b} = \begin{bmatrix} 3 \\ 1 \end{bmatrix}\). Since \(\det(A) = -3 \neq 0\), \(A\) is invertible. We find that \(A^{-1} = \frac{1}{-3} \begin{bmatrix} -1 & -1 \\ -1 & 2 \end{bmatrix}\).
Then, the solution is
Answer and justification for E2.3.1: While
the matrix \(Q\) is not square. Therefore, \(Q\) is not an orthogonal matrix.
Answer and justification for E2.3.3:
Answer and justification for E2.3.5: The projection of \(\mathbf{v}\) onto \(\mathbf{u}\) is given by
Answer and justification for E2.3.7: Using the orthonormal basis \(\{\mathbf{q}_1, \mathbf{q}_2\}\) for \(U\) from the text, we have: $\(\mathrm{proj}_U \mathbf{v} = \langle \mathbf{v}, \mathbf{q}_1 \rangle \mathbf{q}_1 + \langle \mathbf{v}, \mathbf{q}_2 \rangle \mathbf{q}_2 = \frac{4}{\sqrt{2}} \cdot \frac{1}{\sqrt{2}}(1, 0, 1) + \frac{5}{\sqrt{6}} \cdot \frac{1}{\sqrt{6}}(-1, 2, 1) = (\frac{7}{3}, \frac{10}{3}, \frac{13}{3}).\)$
Answer and justification for E2.3.9: From E2.3.7 and E2.3.8, we have:
Computing the squared norms:
Indeed, \(\|\mathbf{v}\|^2 = 14 = \frac{146}{3} + \frac{2}{3} = \|\mathrm{proj}_U \mathbf{v}\|^2 + \|\mathbf{v} - \mathrm{proj}_U \mathbf{v}\|^2\), verifying the Pythagorean theorem.
Answer and justification for E2.3.11: Since \(\mathbf{u}_1\) is not a unit vector, we first normalize it: \(\mathbf{q}_1 = \frac{\mathbf{u}_1}{\|\mathbf{u}_1\|} = \frac{1}{3}\begin{pmatrix} 2 \\ 1 \\ -2 \end{pmatrix}\). Then, \(\mathrm{proj}_{\mathbf{u}_1} \mathbf{u}_2 = \langle \mathbf{u}_2, \mathbf{q}_1 \rangle \mathbf{q}_1 = \frac{1}{9} \begin{pmatrix} 2 \\ 1 \\ -2 \end{pmatrix}\).
Answer and justification for E2.3.13: We want to find all vectors \(\begin{pmatrix} x \\ y \\ z \end{pmatrix}\) such that \(\begin{pmatrix} x \\ y \\ z \end{pmatrix} \cdot \begin{pmatrix} 1 \\ 1 \\ 0 \end{pmatrix} = 0\). This gives us the equation \(x + y = 0\), or \(x = -y\). Thus, any vector of the form \(\begin{pmatrix} -y \\ y \\ z \end{pmatrix} = y\begin{pmatrix} -1 \\ 1 \\ 0 \end{pmatrix} + z\begin{pmatrix} 0 \\ 0 \\ 1 \end{pmatrix}\) is in \(W^\perp\). So, a basis for \(W^\perp\) is \(\left\{\begin{pmatrix} -1 \\ 1 \\ 0 \end{pmatrix}, \begin{pmatrix} 0 \\ 0 \\ 1 \end{pmatrix}\right\}\).
Answer and justification for E2.3.15:
Thus, \(\mathbf{x} = (A^T A)^{-1} A^T \mathbf{b} = \begin{pmatrix} 2 & 0 \\ 0 & 2 \end{pmatrix}^{-1} \begin{pmatrix} 4 \\ 2 \end{pmatrix} = \begin{pmatrix} 2 \\ 1 \end{pmatrix}\).
Answer and justification for E2.4.1: \(\mathbf{q}_1 = \frac{\mathbf{a}_1}{\|\mathbf{a}_1\|} = (1, 0)\), \(\mathbf{v}_2 = \mathbf{a}_2 - \langle \mathbf{q}_1, \mathbf{a}_2 \rangle \mathbf{q}_1 = (0, 1)\), \(\mathbf{q}_2 = \frac{\mathbf{v}_2}{\|\mathbf{v}_2\|} = (0, 1)\).
Answer and justification for E2.4.3: Let \(\mathbf{w}_1 = (1, 1)\) and \(\mathbf{w}_2 = (1, 0)\). Then
So \(\{\mathbf{q}_1, \mathbf{q}_2\}\) is an orthonormal basis.
Answer and justification for E2.4.5: Using the orthonormal basis \(\{\mathbf{q}_1, \mathbf{q}_2\}\) from E2.4.4, we have \(Q = [\mathbf{q}_1\ \mathbf{q}_2]\). To find \(R\), we observe that \(\mathbf{a}_1 = \sqrt{3}\mathbf{q}_1\) and \(\mathbf{a}_2 = \frac{1}{\sqrt{3}}\mathbf{q}_1 + \frac{5}{\sqrt{21}}\mathbf{q}_2\). Therefore, \(R = \begin{pmatrix} \sqrt{3} & \frac{1}{\sqrt{3}} \\ 0 & \frac{5}{\sqrt{21}} \end{pmatrix}\).
Answer and justification for E2.4.7: \(\mathbf{x} = (2, 1)\). From the second equation, \(3x_2 = 3\), so \(x_2 = 1\). Substituting into the first equation, \(2x_1 - 1 = 4\), so \(x_1 = 2\).
Answer and justification for E2.4.9: \(H = I_{3 \times 3} - 2\mathbf{z}\mathbf{z}^T/\|\mathbf{z}\|^2 = \begin{pmatrix} 0 & 1 & 0 \\ 1 & 0 & 0 \\ 0 & 0 & 1 \end{pmatrix}\).
Answer and justification for E2.4.11: To verify that \(H_1\) is orthogonal, we check if \(H_1^T H_1 = I_{2 \times 2}\):
To verify that \(H_1\) is symmetric, we check if \(H_1^T = H_1\), which is true by observation.
Answer and justification for E2.4.13: We have \(H_1 A = R\), where \(R = \begin{pmatrix} -\frac{\sqrt{10}}{5} & -\frac{2}{\sqrt{10}} \\ 0 & \frac{14}{5} \end{pmatrix}\) is upper triangular. Therefore, \(Q^T = H_1\), and \(Q = H_1^T = \begin{pmatrix} \frac{7}{5} & \frac{6}{5} \\ -\frac{6}{5} & \frac{1}{5} \end{pmatrix}\).
Answer and justification for E2.4.15: Let \(\mathbf{y}_1 = (3, 4)^T\) be the first column of \(A\). Then \(\mathbf{z}_1 = \|\mathbf{y}_1\| \mathbf{e}_1^{(2)} - \mathbf{y}_1 = (5, -4)^T\) and \(H_1 = I_{2 \times 2} - 2\mathbf{z}_1\mathbf{z}_1^T / \|\mathbf{z}_1\|^2 = \begin{pmatrix} 3/5 & 4/5 \\ 4/5 & -3/5 \end{pmatrix}\). We can verify that \(H_1 A = \begin{pmatrix} 5 & 1 \\ 0 & -2/5 \end{pmatrix}\).
Answer and justification for E2.4.17:
The solution is \(\mathbf{x} = \begin{pmatrix} 1 \\ 1 \end{pmatrix}\).
Answer and justification for E2.5.1:
The normal equations are:
Solving this system of equations yields \(\beta_0 = \frac{1}{2}\) and \(\beta_1 = \frac{3}{2}\).
Answer and justification for E2.5.3:
Answer and justification for E2.5.5:
We solve the linear system by inverting \(A^T A\) and multiplying by \(A^T \mathbf{y}\).
Answer and justification for E2.5.7:
For a quadratic model, we need columns for \(1\), \(x\), and \(x^2\).
Answer and justification for E2.5.9: We solve the normal equations \(A^T A \boldsymbol{\beta} = A^T \mathbf{y}\).
Solving \(\begin{pmatrix} 3 & 6 \\ 6 & 14 \end{pmatrix} \boldsymbol{\beta} = \begin{pmatrix} 6 \\ 14 \end{pmatrix}\):
Answer and justification for E2.5.11: Compute the predicted \(y\) values:
Compute the residuals:
RSS is:
2.7.1.5. Learning outcomes#
Define the concepts of linear subspaces, spans, and bases in vector spaces.
Check the conditions for a set of vectors to be linearly independent or form a basis of a vector space.
Define the inverse of a nonsingular matrix and prove its uniqueness.
Define the dimension of a linear subspace.
State the Pythagorean Theorem.
Verify whether a given list of vectors is orthonormal.
Derive the coefficients in an orthonormal basis expansion of a vector.
Apply the Gram-Schmidt process to transform a basis into an orthonormal basis.
Prove key theorems related to vector spaces and matrix inverses, such as the Pythagorean theorem for orthogonal vectors and the conditions for linear independence in matrix columns.
Illustrate examples of linear subspaces and their bases, using both theoretical definitions and numerical examples.
Define the orthogonal projection of a vector onto a linear subspace and characterize it geometrically.
Compute the orthogonal projection of a vector onto a linear subspace spanned by an orthonormal list of vectors.
Illustrate the process of finding the orthogonal projection of a vector onto a subspace using geometric intuition.
Prove the uniqueness of the orthogonal projection.
Express the orthogonal projection in matrix form.
Define the orthogonal complement of a linear subspace and find an orthonormal basis for it.
State and prove the Orthogonal Decomposition Lemma, and use it to decompose a vector into its orthogonal projection and a vector in the orthogonal complement.
Formulate the linear least squares problem as an optimization problem and derive the normal equations.
Apply the concepts of orthogonal projection and orthogonal complement to solve overdetermined systems using the least squares method.
Determine the uniqueness of the least squares solution based on the linear independence of the columns of the matrix.
Implement the Gram-Schmidt algorithm to obtain an orthonormal basis from a set of linearly independent vectors.
Express the Gram-Schmidt algorithm using a matrix factorization perspective, known as the QR decomposition.
Apply the QR decomposition to solve linear least squares problems as an alternative to the normal equations approach.
Define Householder reflections and explain their role in introducing zeros below the diagonal of a matrix.
Construct a QR decomposition using a sequence of Householder transformations.
Compare the numerical stability of the Gram-Schmidt algorithm and the Householder transformations approach for computing the QR decomposition.
Formulate the linear regression problem as a linear least squares optimization problem.
Extend the linear regression model to polynomial regression by incorporating higher-degree terms and interaction terms in the design matrix.
Recognize and explain the issue of overfitting in polynomial regression and its potential consequences.
Apply the least squares method to simulated data and real-world datasets, such as the Advertising dataset, to estimate regression coefficients.
Understand and implement the bootstrap method for linear regression to assess the variability of estimated coefficients and determine the statistical significance of the results.
\(\aleph\)
2.7.2. Additional sections#
2.7.2.1. Orthogonality in high dimension#
In high dimension, orthogonality – or more accurately near-orthogonality – is more common than one might expect. We illustrate this phenomenon here.
Let \(\mathbf{X}\) be a standard Normal \(d\)-vector. Its joint PDF depends only on the its norm \(\|\mathbf{X}\|\). So \(\mathbf{Y} = \frac{\mathbf{X}}{\|\mathbf{X}\|}\) is uniformly distributed over the \((d-1)\)-sphere \(\mathcal{S} = \{\mathbf{x}\in \mathbb{R}^d:\|\mathbf{x}\|=1\}\), that is, the surface of the unit \(d\)-ball centered aroungd the origin. We write \(\mathbf{Y} \sim \mathrm{U}[\mathcal{S}]\). The following theorem shows that if we take two independent samples \(\mathbf{Y}_1, \mathbf{Y}_2 \sim \mathrm{U}[\mathcal{S}]\) they are likely to be nearly orthogonal when \(d\) is large, that is, \(|\langle\mathbf{Y}_1, \mathbf{Y}_2\rangle|\) is likely to be small. By symmetry, there is no loss of generality in taking one of the two vectors to be the north pole \(\mathbf{e}_d = (0,\ldots,0,1)\). A different way to state the theorem is that most of the mass of the \((d-1)\)-sphere is in a small band around the equator.
Figure: Band around the equator (Source)
{kind=link}
\(\bowtie\)
THEOREM (Orthogonality in High Dimension) Let \(\mathcal{S} = \{\mathbf{x}\in \mathbb{R}^d:\|\mathbf{x}\|=1\}\) and \(\mathbf{Y} \sim \mathrm{U}[\mathcal{S}]\). Then for any \(\varepsilon > 0\), as \(d \to +\infty\),
\(\sharp\)
Proof idea: We write \(\mathbf{Y}\) in terms of a standard Normal. Its squared norm is a sum of independent random variables. After bringing it to the numerator, we can apply Chebyshev.
Proof: Recall that \(\mathbf{Y}\) is \(\frac{\mathbf{X}}{\|\mathbf{X}\|}\) where \(\mathbf{X}\) is a standard Normal \(d\)-vector. The probability we want to bound can be re-written as
We are now looking at a sum of independent (but not identically distributed) random variables
and we can appeal to our usual Chebyshev machinery. The expectation is, by linearity,
where we used that \(X_1,\ldots,X_d\) are standard Normal variables and that, in particular, their mean is \(0\) and their variance is \(1\) so that \(\mathbb{E}[X_1^2] = 1\).
The variance is, by independence of the \(X_j\)’s,
So by Chebyshev
as \(d \to +\infty\). To get the limit we observed that, for large \(d\), the deminator scales like \(d^2\) while the numerator scales only like \(d\). \(\square\)
2.7.2.2. Bootstrapping for linear regression#
We return to the linear case, but with the full set of predictors.
data = pd.read_csv('advertising.csv')
TV = data['TV'].to_numpy()
sales = data['sales'].to_numpy()
n = np.size(TV)
radio = data['radio'].to_numpy()
newspaper = data['newspaper'].to_numpy()
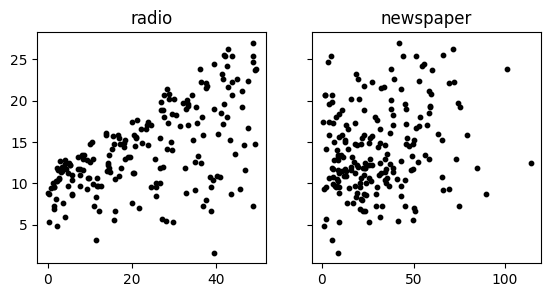
f, (ax1, ax2) = plt.subplots(1, 2, sharex=False, sharey=True, figsize=(6.5,3))
ax1.scatter(radio, sales, s=10, c='k')
ax2.scatter(newspaper, sales, s=10, c='k')
ax1.set_title('radio'), ax2.set_title('newspaper')
plt.show()
A = np.stack((np.ones(n), TV, radio, newspaper), axis=-1)
coeff = mmids.ls_by_qr(A,sales)
print(coeff)
[ 2.93888937e+00 4.57646455e-02 1.88530017e-01 -1.03749304e-03]
Newspaper advertising (the last coefficient) seems to have a much weaker effect on sales per dollar spent. Next, we briefly sketch one way to assess the statistical significance of such a conclusion.
Our coefficients are estimated from a sample. There is intrinsic variability in our sampling procedure. We would like to understand how our estimated coefficients compare to the true coefficients. This is set up beautifully in [Data8, Section 13.2]:
A data scientist is using the data in a random sample to estimate an unknown parameter. She uses the sample to calculate the value of a statistic that she will use as her estimate. Once she has calculated the observed value of her statistic, she could just present it as her estimate and go on her merry way. But she’s a data scientist. She knows that her random sample is just one of numerous possible random samples, and thus her estimate is just one of numerous plausible estimates. By how much could those estimates vary? To answer this, it appears as though she needs to draw another sample from the population, and compute a new estimate based on the new sample. But she doesn’t have the resources to go back to the population and draw another sample. It looks as though the data scientist is stuck. Fortunately, a brilliant idea called the bootstrap can help her out. Since it is not feasible to generate new samples from the population, the bootstrap generates new random samples by a method called resampling: the new samples are drawn at random from the original sample.
Without going into full details (see [DS100, Section 17.3] for more), it works as follows. Let \(\{(\mathbf{x}_i, y_i)\}_{i=1}^n\) be our data. We assume that our sample is representative of the population and we simulate our sampling procedure by resampling from the sample. That is, we take a random sample with replacement \(\mathcal{X}_{\mathrm{boot},1} = \{(\mathbf{x}_i, y_i)\,:\,i \in I\}\) where \(I\) is a multi-set of elements from \([n]\) of size \(n\). We recompute our estimated coefficients on \(\mathcal{X}_{\mathrm{boot},1}\). Then we repeat independently for a desired number of replicates \(\mathcal{X}_{\mathrm{boot},1}, \ldots, \mathcal{X}_{\mathrm{boot},r}\). Plotting a histogram of the resulting coefficients gives some idea of the variability of our estimates.
We implement the bootstrap for linear regression in Python next.
def linregboot(rng, A, b, replicates = np.int32(10000)):
n,m = A.shape
coeff_boot = np.zeros((m,replicates))
for i in range(replicates):
resample = rng.integers(0,n,n)
Aboot = A[resample,:]
bboot = b[resample]
coeff_boot[:,i] = mmids.ls_by_qr(Aboot,bboot)
return coeff_boot
First, let’s use a simple example with a known ground truth.
seed = 535
rng = np.random.default_rng(seed)
n, b0, b1 = 100, -1, 1
x = np.linspace(0,10,num=n)
y = b0 + b1*x + rng.normal(0,1,n)
A = np.stack((np.ones(n),x),axis=-1)
The estimated coefficients are the following.
coeff = mmids.ls_by_qr(A,y)
print(coeff)
[-1.03381171 1.01808039]
Now we apply the bootstrap and plot histograms of the two coefficients.
coeff_boot = linregboot(rng, A,y)
f, (ax1, ax2) = plt.subplots(1, 2, sharex=False, sharey=True, figsize=(7,3))
ax1.hist(coeff_boot[0,:], bins=20, color='lightblue', edgecolor='black')
ax2.hist(coeff_boot[1,:], bins=20, color='lightblue', edgecolor='black')
ax1.set_title('coeff1'), ax2.set_title('coeff2')
plt.show()
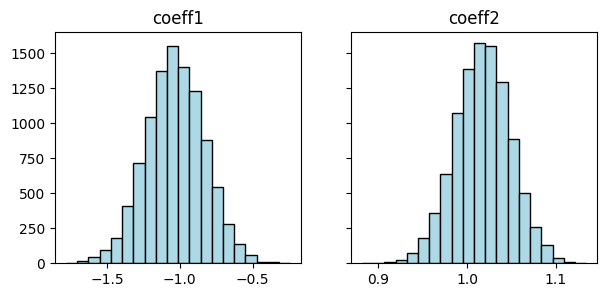
We see in the histograms that the true coefficient values \(-1\) and \(1\) fall within the likely range.
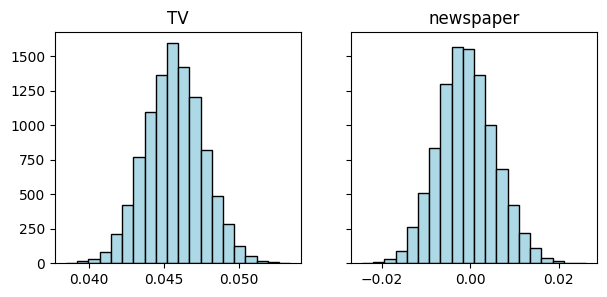
We return to the Advertising dataset and apply the bootstrap. Plotting a histogram of the coefficients corresponding to newspaper advertising shows that \(0\) is a plausible value, while it is not for TV advertising.
n = np.size(TV)
A = np.stack((np.ones(n), TV, radio, newspaper), axis=-1)
coeff = mmids.ls_by_qr(A,sales)
print(coeff)
[ 2.93888937e+00 4.57646455e-02 1.88530017e-01 -1.03749304e-03]
coeff_boot = linregboot(rng, A,sales)
f, (ax1, ax2) = plt.subplots(1, 2, sharex=False, sharey=True, figsize=(7,3))
ax1.hist(coeff_boot[1,:], bins=20, color='lightblue', edgecolor='black')
ax2.hist(coeff_boot[3,:], bins=20, color='lightblue', edgecolor='black')
ax1.set_title('TV'), ax2.set_title('newspaper')
plt.show()