
\(\newcommand{\bmu}{\boldsymbol{\mu}}\) \(\newcommand{\bSigma}{\boldsymbol{\Sigma}}\) \(\newcommand{\bfbeta}{\boldsymbol{\beta}}\) \(\newcommand{\bflambda}{\boldsymbol{\lambda}}\) \(\newcommand{\bgamma}{\boldsymbol{\gamma}}\) \(\newcommand{\bsigma}{{\boldsymbol{\sigma}}}\) \(\newcommand{\bpi}{\boldsymbol{\pi}}\) \(\newcommand{\btheta}{{\boldsymbol{\theta}}}\) \(\newcommand{\bphi}{\boldsymbol{\phi}}\) \(\newcommand{\balpha}{\boldsymbol{\alpha}}\) \(\newcommand{\blambda}{\boldsymbol{\lambda}}\) \(\renewcommand{\P}{\mathbb{P}}\) \(\newcommand{\E}{\mathbb{E}}\) \(\newcommand{\indep}{\perp\!\!\!\perp} \newcommand{\bx}{\mathbf{x}}\) \(\newcommand{\bp}{\mathbf{p}}\) \(\renewcommand{\bx}{\mathbf{x}}\) \(\newcommand{\bX}{\mathbf{X}}\) \(\newcommand{\by}{\mathbf{y}}\) \(\newcommand{\bY}{\mathbf{Y}}\) \(\newcommand{\bz}{\mathbf{z}}\) \(\newcommand{\bZ}{\mathbf{Z}}\) \(\newcommand{\bw}{\mathbf{w}}\) \(\newcommand{\bW}{\mathbf{W}}\) \(\newcommand{\bv}{\mathbf{v}}\) \(\newcommand{\bV}{\mathbf{V}}\) \(\newcommand{\bfg}{\mathbf{g}}\) \(\newcommand{\bfh}{\mathbf{h}}\) \(\newcommand{\horz}{\rule[.5ex]{2.5ex}{0.5pt}}\) \(\renewcommand{\S}{\mathcal{S}}\) \(\newcommand{\X}{\mathcal{X}}\) \(\newcommand{\var}{\mathrm{Var}}\) \(\newcommand{\pa}{\mathrm{pa}}\) \(\newcommand{\Z}{\mathcal{Z}}\) \(\newcommand{\bh}{\mathbf{h}}\) \(\newcommand{\bb}{\mathbf{b}}\) \(\newcommand{\bc}{\mathbf{c}}\) \(\newcommand{\cE}{\mathcal{E}}\) \(\newcommand{\cP}{\mathcal{P}}\) \(\newcommand{\bbeta}{\boldsymbol{\beta}}\) \(\newcommand{\bLambda}{\boldsymbol{\Lambda}}\) \(\newcommand{\cov}{\mathrm{Cov}}\) \(\newcommand{\bfk}{\mathbf{k}}\) \(\newcommand{\idx}[1]{}\) \(\newcommand{\xdi}{}\)
5.5. Application: graph partitioning via spectral clustering#
In this section, we use the spectral properties of the Laplacian of a graph to identify “good” cuts.
5.5.1. How to cut a graph#
Let \(G=(V, E)\) be a graph. Imagine that we are interested in finding a good cut. That is, roughly speaking, we seek to divide it into two disjoint subsets of vertices to achieve two goals simultaneously:
the two sets have relatively few edges between them
neither set is too small.
We will show that the Laplacian eigenvectors provide useful information in order to perform this kind of graph cutting. First we formulate the problem formally.
Cut ratio One way to make the graph cutting more precise is to consider the following combinatorial quantity.
DEFINITION (Isoperimetric Number) \(\idx{isoperimetric number}\xdi\) Let \(G=(V, E)\) be a graph. A cut\(\idx{cut}\xdi\) is a bipartition \((S, S^c)\) of the vertices of \(G\), where \(S\) and \(S^c = V\setminus S\) are non-empty subsets of \(V\). The corresponding cutset is the set of edges between \(S\) and \(S^c\)
This is also known as the edge boundary of \(S\) (denoted \(\partial S\)). The size of the cutset\(\idx{cutset}\xdi\) is then \(|E(S,S^c)|\), the number of edges between \(S\) to \(S^c\). The cut ratio\(\idx{cut ratio}\xdi\) of \((S,S^c)\) is defined as
and the isoperimetric number (or Cheeger constant)\(\idx{Cheeger constant}\xdi\) of \(G\) is the smallest value this quantity can take on \(G\), that is,
\(\natural\)
In words: the cut ratio is attempting to minimize the number of edges across a cut, while penalizing cuts with a small number of vertices on either side. These correspond to the goals above and we will use this criterion to assess the quality of graph cuts.
Why do we need the denominator? If we were to minimize only the numerator \(|E(S,S^c)|\) over all cuts (without the deonominator in \(\phi(S)\)), we would get what is known as the minimum cut (or min-cut) problem. That problem is easier to solve. In particular, it can be solved using a beautiful randomized algorithm. However, it tends to produce unbalanced cuts, where one side is much smaller than the other. This is not what we want here.
Figure: Bridges are a good example of a bottleneck (i.e., a good cut) in a transportation network. (Credit: Made with Midjourney)

\(\bowtie\)
EXAMPLE: (A Random Tree) We illustrate the definitions above on a tree, that is, a connected graph with no cycle. The function networkx.random_labeled_tree can produce a random one. As before we use a seed for reproducibility. Again, we use \(0,\ldots,n-1\) for the vertex set.
G_tree = nx.random_labeled_tree(n=6, seed=111)
nx.draw_networkx(G_tree, pos=nx.circular_layout(G_tree),
node_color='black', font_color='white')
plt.axis('off')
plt.show()
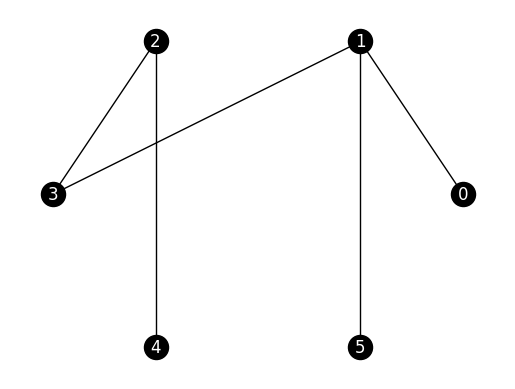
Suppose we take \(S = \{0,1,2,3\}\). Then \(S^c = \{4,5\}\) and
The cut ratio is then
A better cut is given by \(S = \{0,1,5\}\). In that case \(S^c = \{2,3,4\}\),
and
This is also equal to \(\phi_G\). Indeed, in a connected graph with \(n\) vertices, the numerator is at least \(1\) and the denominator is at most \(n/2\), which is achieved here.
\(\lhd\)
Cheeger’s inequalities A key result of spectral graph theory establishes a quantitative relation between the isoperimetric number and the second smallest Laplacian eigenvalue.
THEOREM (Cheeger) \(\idx{Cheeger's inequality}\xdi\) Let \(G = (V, E)\) be a graph with \(n = |V|\) vertices and maximum degree \(\bar{\delta}\). Let \(0 = \mu_1 \leq \mu_2 \leq \cdots \leq \mu_n\) be its Laplacian eigenvalues. Then
\(\sharp\)
We only prove the easy direction, \(\mu_2 \leq 2 \phi_G\), which shows explicitly how the connection between \(\mu_2\) and \(\phi_G\) comes about.
Proof idea: To show that \(\mu_2 \leq 2 \phi_G\), we find an appropriate test vector to plug into the extremal characterization of \(\mu_2\) and link it to \(\phi_G\).
Proof: Recall that, from the Variational Characterization of \(\mu_2\), we have
Constructing a good test vector: We construct an \(\mathbf{x}\) that provides a good upper bound. Let \(\emptyset \neq S \subset V\) be a proper, nonempty subset of \(V\) such that \(0 < |S| \leq \frac{1}{2}|V|\). We choose a vector that takes one value on \(S\) and a different value on \(S^c\). Taking a cue from the two-component example above we consider the vector with entries
This choice ensures that
as well
To evaluate the Laplacian quadratic form, we note that \(\mathbf{x}\) takes the same value everywhere on \(S\) (and on \(S^c\)). Hence the sum over edges reduces to
where we used that, for each edge \(\{i, j\} \in E\) where \(x_i \neq x_j\), one endvertex is in \(S\) and one endvertex is in \(S^c\).
Using the definition of the isoperimetric number: So for this choice of \(\mathbf{x}\) we have
where we used that \(|S^c| \geq n/2\). This inequality holds for any \(S\) such that \(0 < |S| \leq \frac{1}{2}|V|\). In particular, it holds for the \(S\) producing the smallest value. Hence, by the definition of the isoperimetric number, we get
as claimed. \(\square\)
NUMERICAL CORNER: We return to the random tree example above. We claimed that \(\phi_G = 1/3\). The maximum degree is \(\bar{\delta} = 3\). We now compute \(\mu_2\). We first compute the Laplacian matrix.
phi_G = 1/3
max_deg = 3
We now compute \(\mu_2\). We first compute the Laplacian matrix.
L_tree = nx.laplacian_matrix(G_tree).toarray()
print(L_tree)
[[ 1 -1 0 0 0 0]
[-1 3 0 -1 0 -1]
[ 0 0 2 -1 -1 0]
[ 0 -1 -1 2 0 0]
[ 0 0 -1 0 1 0]
[ 0 -1 0 0 0 1]]
w, v = LA.eigh(L_tree)
mu_2 = np.sort(w)[1]
print(mu_2)
0.32486912943335317
We check Cheeger’s inequalities. The left-hand side is:
(phi_G ** 2) / (2 * max_deg)
0.018518518518518517
The right-hand side is:
2 * phi_G
0.6666666666666666
\(\unlhd\)
A graph-cutting algorithm We only proved the easy direction of Cheeger’s inequalities. It is however useful to sketch the other direction (the actual Cheeger’s inequality in the graph context), as it contains an important algorithmic idea.
An algorithm: The input is the graph \(G=(V,E)\). Let \(\mathbf{y}_2 \in \mathbb{R}^n\) be the unit-norm eigenvector of the Laplacian matrix \(L\) associated to its second smallest eigenvalue \(\mu_2\), i.e., \(\mathbf{y}_2\) is the Fiedler vector. There is one entry of \(\mathbf{y}_2 = (y_{2,1}, \ldots, y_{2,n})\) for each vertex of \(G\). We use these entries to embed the graph \(G\) in \(\mathbb{R}\): vertex \(i\) is mapped to \(y_{2,i}\). Now order the entries \(y_{2,\pi(1)}, \ldots, y_{2,\pi(n)}\), where \(\pi\) is a permutation\(\idx{permutation}\xdi\), that is, a re-ordering of \(1,\ldots,n\). Specifically, \(\pi(1)\) is the vertex corresponding to the smallest entry of \(\mathbf{y}_{2}\), \(\pi(2)\) is the second smallest, and so on. We consider only cuts of the form
and we output the cut \((S_k, S_k^c)\) that minimizes the cut ratio
for the \(k \leq n-1\).
What can be proved rigorously (but we will not do this here) is that there exists some \(k^* \in\{1,\ldots,n-1\}\) such that
which implies the lower bound in Cheeger’s inequalities. The leftmost inequality is the non-trivial one.
Since \(\mu_2 \leq 2 \phi_G\), this implies that
So \(\phi(S_{k^*})\) may not achieve \(\phi_G\), but we do get some guarantee on the quality of the cut produced by this algorithm.
See, for example, [Kel, Lecture 3, Section 4.2] for more details.
The above provides a heuristic to find a cut with provable guarantees. We implement it next. In contrast, the problem of finding a cut which minimizes the cut ratio is known to be NP-hard\(\idx{NP-hardness}\xdi\), that is, roughly speaking it is computationally intractable.
We implement the graph cutting algorithm above.
We now implement this heuristic in Python. We first write an auxiliary function that takes as input an adjacency matrix, an ordering of the vertices and a value \(k\). It returns the cut ratio for the first \(k\) vertices in the order.
def cut_ratio(A, order, k):
n = A.shape[0]
edge_boundary = 0
for i in range(k+1):
for j in range(k+1,n):
edge_boundary += A[order[i],order[j]]
denominator = np.minimum(k+1, n-k-1)
return edge_boundary/denominator
Using the cut_ratio function, we first compute the Laplacian, find the second eigenvector and corresponding order of vertices. Then we compute the cut ratio for every \(k\). Finally we output the cut (both \(S_k\) and \(S_k^c\)) corresponding to the minimum, as a tuple of arrays.
def spectral_cut2(A):
n = A.shape[0]
degrees = A.sum(axis=1)
D = np.diag(degrees)
L = D - A
w, v = LA.eigh(L)
order = np.argsort(v[:,np.argsort(w)[1]])
phi = np.zeros(n-1)
for k in range(n-1):
phi[k] = cut_ratio(A, order, k)
imin = np.argmin(phi)
return order[0:imin+1], order[imin+1:n]
Finally, to help visualize the output, we write a function coloring the vertices according to which side of the cut they are on.
def viz_cut(G, s, pos, node_size=100, with_labels=False):
n = G.number_of_nodes()
assign = np.zeros(n)
assign[s] = 1
nx.draw(G, node_color=assign, pos=pos, with_labels=with_labels,
cmap='spring', node_size=node_size, font_color='k')
plt.show()
NUMERICAL CORNER: We will illustrate this on the path graph.
n = 10
G = nx.path_graph(n)
nx.draw_networkx(G, pos=nx.spectral_layout(G),
node_color='black', font_color='white')
plt.axis('off')
plt.show()
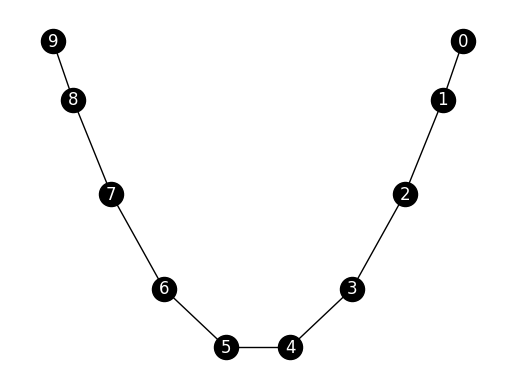
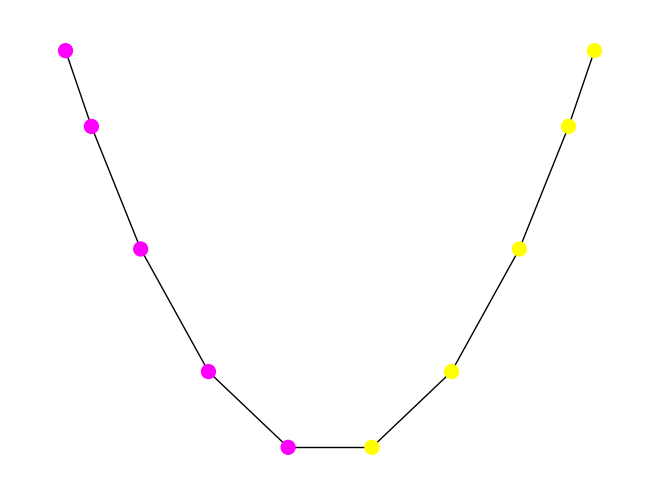
We apply our spectral-based cutting algorihtm.
A = nx.adjacency_matrix(G).toarray()
s, sc = spectral_cut2(A)
print(s)
print(sc)
[0 1 2 3 4]
[5 6 7 8 9]
pos = nx.spectral_layout(G)
viz_cut(G, s, pos)
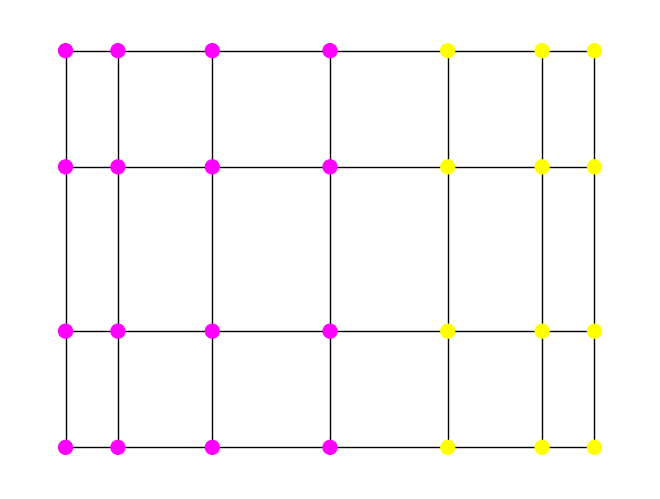
Let’s try it on the grid graph. Can you guess what the cut will be?
G = nx.grid_2d_graph(4,7)
A = nx.adjacency_matrix(G).toarray()
s, sc = spectral_cut2(A)
pos = nx.spectral_layout(G)
viz_cut(G, s, pos)
\(\unlhd\)
How to compute the second smallest eigenvalue? There is one last piece of business to take care of. How do we compute the Fiedler vector? Previously, we have seen an iterative approach based on taking powers of the matrix to compute the largest eigenvalue and corresponding eigenvector of a positive semidefinite matrix. We show here how to adapt this approach to our task at hand. The details are left as a series of exercises.
First, we modify the Laplacian matrix to invert the order of the eigenvalues without changing the eigenvectors themselves. This way the smallest eigenvalues will become the largest ones. By the Laplacian and Maximum Degree Lemma, \(\mu_i \leq 2 \bar{\delta}\) for all \(i=1,\ldots,n\), where recall that \(\bar{\delta}\) is the largest degree of the graph.
LEMMA (Inverting the Order of Eigenvalues) \(\idx{inverting the order of eigenvalues lemma}\xdi\) For \(i=1,\ldots,n\), let \(\lambda_i = 2 \bar{\delta} - \mu_i\). The matrix \(M = 2 \bar{\delta} I_{n\times n} - L\) is positive semidefinite and has eigenvector decomposition
\(\flat\)
Second, our goal is now to compute the second largest eigenvalue of \(M\) – not the largest one. But we already know the largest one. It is \(\lambda_1 = 2\bar{\delta} - \mu_1 = 2 \bar{\delta}\) and its associated eigenvector is \(\mathbf{y}_1 = \frac{1}{\sqrt{n}}(1,\ldots,1)\). It turns out that we can simply apply power iteration with a starting vector that is orthogonal to \(\mathbf{y}_1\). Such a vector can be constructed by taking a random vector and subtracting its orthogonal projection on \(\mathbf{y}_1\).
LEMMA (Power Iteration for the Second Largest Eigenvalue) Assume that \(\mu_1 < \mu_2 < \mu_3\). Let \(\mathbf{x} \in \mathbb{R}^n\) be a vector such that \(\langle \mathbf{y}_1, \mathbf{x} \rangle = 0\) and \(\langle \mathbf{y}_2, \mathbf{x} \rangle > 0\). Then
as \(k \to +\infty\). If instead \(\langle \mathbf{y}_2, \mathbf{x} \rangle < 0\), then the limit is \(- \mathbf{y}_2\). \(\flat\)
The relaxation perspective Here is another intuitive way to shed light on the effectiveness of spectral partitioning. Assume we have a graph \(G = (V,E)\) with an even number \(n = |V|\) of vertices. Suppose we are looking for the best balanced cut \((S,S^c)\) in the sense that it minimizes the number of edges \(|E(S,S^c)|\) across it over all cuts with \(|S| = |S^c| = n/2\). This is known as the minimum bisection problem.
Mathematically, we can formulate this as the followign discrete optimization problem:
The condition \(\mathbf{x} \in \{-1,+1\}^n\) implicitly assigns each vertex \(i\) to \(S\) (if \(x_i = -1\)) or \(S^c\) (if \(x_i=+1\)). The condition \(\sum_{i=1}^n x_i = 0\) then ensures that the cut \((S,S^c)\) is balanced, that is, that \(|S| = |S^c|\). Under this interpretation, the term \((x_i - x_j)^2\) is either \(0\) if \(i\) and \(j\) are on the same side of the cut, or \(4\) if they are on opposite sides.
This is a hard computational problem. One way to approach such a discrete optimization problem is to relax it. That is, to turn it into an optimization problem with continuous variables. Specifically here we consider instead
The optimal objective value of this relaxed problem is necessarily smaller or equal than the original one. Indeed any solution to the original problem satisfies the constraints of the relaxation. Up to a scaling factor, this last problem is equivalent to the variational characterization of \(\mu_2\). Indeed, one can prove that the minimum achieved is \(\frac{\mu_2 n}{4}\) (Try it!).
NUMERICAL CORNER: We return to the Karate Club dataset.
Figure: Dojo (Credit: Made with Midjourney)

\(\bowtie\)
G = nx.karate_club_graph()
n = G.number_of_nodes()
A = nx.adjacency_matrix(G).toarray()
We seek to find natural sub-communities. We use the spectral properties of the Laplacian. Specifically, we use our spectral_cut2 and viz_cut functions to compute a good cut and vizualize it.
s, sc = spectral_cut2(A)
print(s)
print(sc)
[18 26 20 14 29 22 24 15 23 25 32 27 9 33 31 28 30 8]
[ 2 13 1 19 7 3 12 0 21 17 11 4 10 6 5 16]
plt.figure(figsize=(6,6))
pos = nx.spring_layout(G, k=0.7, iterations=50, seed=42)
viz_cut(G, s, pos, node_size=300, with_labels=True)
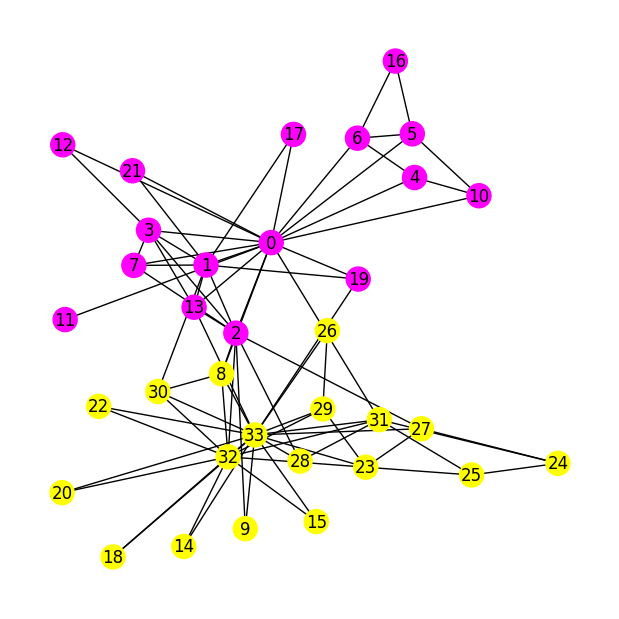
It is not trivial to assess the quality of the resulting cut. But this particular example has a known ground-truth community structure (which partly explains its widespread use). Quoting from Wikipedia:
A social network of a karate club was studied by Wayne W. Zachary for a period of three years from 1970 to 1972. The network captures 34 members of a karate club, documenting links between pairs of members who interacted outside the club. During the study a conflict arose between the administrator “John A” and instructor “Mr. Hi” (pseudonyms), which led to the split of the club into two. Half of the members formed a new club around Mr. Hi; members from the other part found a new instructor or gave up karate. Based on collected data Zachary correctly assigned all but one member of the club to the groups they actually joined after the split.
This ground truth is the following. We use numpy.nonzero to convert it into a cut.
truth = np.array([0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 0,
0, 1, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1])
s_truth = np.nonzero(truth)
plt.figure(figsize=(6,6))
viz_cut(G, s_truth, pos, node_size=300, with_labels=True)
You can check that our cut perfectly matches the ground truth.
CHAT & LEARN Investigate alternative graph partitioning algorithms, such as the Kernighan-Lin algorithm. Ask your favorite AI chatbot to explain how it works and compare its performance to spectral clustering on this dataset. (Open In Colab) \(\ddagger\)
\(\unlhd\)
Self-assessment quiz (with help from Claude, Gemini, and ChatGPT)
1 Which of the following best describes the ‘cut ratio’ of a graph cut \((S, S^c)\)?
a) The ratio of the number of edges between \(S\) and \(S^c\) to the total number of edges in the graph.
b) The ratio of the number of edges between \(S\) and \(S^c\) to the size of the smaller set, \(\min\{|S|, |S^c|\}\).
c) The ratio of the number of edges within \(S\) to the number of edges within \(S^c\).
d) The ratio of the total number of edges in the graph to the number of edges between \(S\) and \(S^c\).
2 What is the isoperimetric number (or Cheeger constant) of a graph \(G\)?
a) The largest value of the cut ratio over all possible cuts.
b) The smallest value of the cut ratio over all possible cuts.
c) The average value of the cut ratio over all possible cuts.
d) The median value of the cut ratio over all possible cuts.
3 What do Cheeger’s inequalities establish?
a) A relationship between the isoperimetric number and the largest Laplacian eigenvalue.
b) A relationship between the isoperimetric number and the second largest Laplacian eigenvalue.
c) A relationship between the isoperimetric number and the smallest Laplacian eigenvalue.
d) A relationship between the isoperimetric number and the second smallest Laplacian eigenvalue.
4 In the context of spectral graph theory, what is the Fiedler vector?
a) The eigenvector associated with the largest eigenvalue of the Laplacian matrix.
b) The eigenvector associated with the smallest eigenvalue of the Laplacian matrix.
c) The eigenvector associated with the second smallest eigenvalue of the Laplacian matrix.
d) The eigenvector associated with the second largest eigenvalue of the Laplacian matrix.
5 Which of the following is the relaxation of the minimum bisection problem presented in the text?
a)
b)
c)
d)
Answer for 1: b. Justification: The text defines the cut ratio as \(\phi(S) = \frac{|E(S, S^c)|}{\min\{|S|, |S^c|\}}\), where \(|E(S, S^c)|\) is the number of edges between \(S\) and \(S^c\).
Answer for 2: b. Justification: The text defines the isoperimetric number as “the smallest value [the cut ratio] can take on \(G\), that is, \(\phi_G = \min_{\emptyset \neq S \subset V} \phi(S)\).”
Answer for 3: d. Justification: The text states that “A key result of spectral graph theory establishes a quantitative relation between the isoperimetric number and the second smallest Laplacian eigenvalue.”
Answer for 4: c. Justification: The text refers to the eigenvector associated with the second smallest eigenvalue of the Laplacian matrix as the Fiedler vector.
Answer for 5: a. Justification: The text replaces the constraint \(\mathbf{x} = (x_1, ..., x_n) \in \{-1, +1\}^n\) with \(\mathbf{x} = (x_1, ..., x_n) \in \mathbb{R}^n\) and adds the constraint \(\sum_{i=1}^n x_i^2 = n\) to maintain the balanced cut property.