
\(\newcommand{\bmu}{\boldsymbol{\mu}}\) \(\newcommand{\bSigma}{\boldsymbol{\Sigma}}\) \(\newcommand{\bfbeta}{\boldsymbol{\beta}}\) \(\newcommand{\bflambda}{\boldsymbol{\lambda}}\) \(\newcommand{\bgamma}{\boldsymbol{\gamma}}\) \(\newcommand{\bsigma}{{\boldsymbol{\sigma}}}\) \(\newcommand{\bpi}{\boldsymbol{\pi}}\) \(\newcommand{\btheta}{{\boldsymbol{\theta}}}\) \(\newcommand{\bphi}{\boldsymbol{\phi}}\) \(\newcommand{\balpha}{\boldsymbol{\alpha}}\) \(\newcommand{\blambda}{\boldsymbol{\lambda}}\) \(\renewcommand{\P}{\mathbb{P}}\) \(\newcommand{\E}{\mathbb{E}}\) \(\newcommand{\indep}{\perp\!\!\!\perp} \newcommand{\bx}{\mathbf{x}}\) \(\newcommand{\bp}{\mathbf{p}}\) \(\renewcommand{\bx}{\mathbf{x}}\) \(\newcommand{\bX}{\mathbf{X}}\) \(\newcommand{\by}{\mathbf{y}}\) \(\newcommand{\bY}{\mathbf{Y}}\) \(\newcommand{\bz}{\mathbf{z}}\) \(\newcommand{\bZ}{\mathbf{Z}}\) \(\newcommand{\bw}{\mathbf{w}}\) \(\newcommand{\bW}{\mathbf{W}}\) \(\newcommand{\bv}{\mathbf{v}}\) \(\newcommand{\bV}{\mathbf{V}}\) \(\newcommand{\bfg}{\mathbf{g}}\) \(\newcommand{\bfh}{\mathbf{h}}\) \(\newcommand{\horz}{\rule[.5ex]{2.5ex}{0.5pt}}\) \(\renewcommand{\S}{\mathcal{S}}\) \(\newcommand{\X}{\mathcal{X}}\) \(\newcommand{\var}{\mathrm{Var}}\) \(\newcommand{\pa}{\mathrm{pa}}\) \(\newcommand{\Z}{\mathcal{Z}}\) \(\newcommand{\bh}{\mathbf{h}}\) \(\newcommand{\bb}{\mathbf{b}}\) \(\newcommand{\bc}{\mathbf{c}}\) \(\newcommand{\cE}{\mathcal{E}}\) \(\newcommand{\cP}{\mathcal{P}}\) \(\newcommand{\bbeta}{\boldsymbol{\beta}}\) \(\newcommand{\bLambda}{\boldsymbol{\Lambda}}\) \(\newcommand{\cov}{\mathrm{Cov}}\) \(\newcommand{\bfk}{\mathbf{k}}\) \(\newcommand{\idx}[1]{}\) \(\newcommand{\xdi}{}\)
7.2. Background: elements of finite Markov chains#
As we mentioned, we are interested in analyzing the behavior of a random walk “diffusing” on a graph. Before we develop such techniques, it will be worthwhile to cast them in the more general framework of discrete-time Markov chains on a finite state space. Indeed Markov chains have many more applications in data science.
7.2.1. Basic definitions#
A discrete-time Markov chain\(\idx{Markov chain}\xdi\) is a stochastic process\(\idx{stochastic process}\xdi\), i.e., a collection of random variables in this case indexed by time. We assume that the random variables take values in a common finite state space \(\S\). What makes it “Markovian” is that “it forgets the past” in the sense that “its future only depends on its present state.” More formally:
DEFINITION (Discrete-Time Markov Chain) The sequence of random variables \((X_t)_{t \geq 0} = (X_0, X_1, X_2, \ldots)\) taking values in the finite state space \(\S\) is a Markov chain if: for all \(t \geq 1\) and all \(x_0,x_1,\ldots,x_t \in \S\)
provided the conditional probabilities are well-defined. \(\natural\)
To be clear, the event in the conditioning is
It will sometimes be convenient to assume that the common state space \(\S\) is of the form \([m] = \{1,\ldots,m\}\).
EXAMPLE: (Weather Model) Here is a simple weather model. Every day is either \(\mathrm{Dry}\) or \(\mathrm{Wet}\). We model the transitions as Markovian; intuitively, we assume that tomorrow’s weather only depends - in a random fashion independent of the past - on today’s weather. Say the weather changes with \(25\%\) chance. More formally, let \(X_t \in \mathcal{S}\) be the weather on day \(t\) with \(\mathcal{S} = \{\mathrm{Dry}, \mathrm{Wet}\}\). Assume that \(X_0 = \mathrm{Dry}\) and let \((Z_t)_{t \geq 0}\) be an i.i.d. (i.e., independent, identically distributed) sequence of random variables taking values in \(\{\mathrm{Same}, \mathrm{Change}\}\) satisfying
Then define for all \(t \geq 0\)
We claim that \((X_t)_{t \geq 0}\) is a Markov chain. We use two observations:
1- By composition,
and, more generally,
is a deterministic function of \(X_0 = \mathrm{Dry}\) and \(Z_0,\ldots,Z_{t-1}\).
2- For any \(x_1,\ldots,x_t \in \S\), there is precisely one value of \(z \in \{\mathrm{Same}, \mathrm{Change}\}\) such that \(x_t = f(x_{t-1}, z)\), i.e., if \(x_t = x_{t-1}\) we must have \(z = \mathrm{Same}\) and if \(x_t \neq x_{t-1}\) we must have \(z = \mathrm{Change}\).
Fix \(x_0 = \mathrm{Dry}\). For any \(x_1,\ldots,x_t \in \S\), letting \(z\) be as in Observation 2,
where we used that \(Z_{t-1}\) is independent of \(Z_{t-2},\ldots,Z_0\) and \(X_0\) (which is deterministic), and therefore is independent of \(X_{t-1},\ldots,X_0\) by Observation 1. The same argument shows that
and that proves the claim.
More generally, one can pick \(X_0\) according to an initial distribution, independently from the sequence \((Z_t)_{t \geq 0}\). The argument above can be adapted to this case. \(\lhd\)
EXAMPLE: (Random Walk on the Petersen Graph) Let \(G = (V,E)\) be the Petersen graph. Each vertex \(i\) has degree \(3\), that is, it has three neighbors which we denote \(v_{i,1}, v_{i,2}, v_{i,3}\) in some arbitrary order. For instance, denoting the vertices by \(1,\ldots, 10\) as above, vertex \(9\) has neighbors \(v_{9,1} = 4, v_{9,2} = 6, v_{9,3} = 7\).
We consider the following random walk on \(G\). We start at \(X_0 = 1\). Then, for each \(t\geq 0\), we let \(X_{t+1}\) be a uniformly chosen neighbor of \(X_t\), independently of the previous history. That is, we jump at random from neighbor to neighbor. Formally, fix \(X_0 = 1\) and let \((Z_t)_{t \geq 0}\) be an i.i.d. sequence of random variables taking values in \(\{1,2,3\}\) satisfying
Then define, for all \(t \geq 0\), \(X_{t+1} = f(X_t, Z_t) = v_{i,Z_t}\) if \(X_t = v_i\).
By an argument similar to the previous example, \((X_t)_{t \geq 0}\) is a Markov chain. Also as in the previous example, one can pick \(X_0\) according to an initial distribution, independently from the sequence \((Z_t)_{t \geq 0}\). \(\lhd\)
There are various useful generalizations of the condition \((*)\) in the definition of a Markov chain. These are all special cases of what is referred to as the Markov Property\(\idx{Markov property}\xdi\) which can be summarized as: the past and the future are independent given the present. We record a version general enough for us here. Let \((X_t)_{t \geq 0}\) be a Markov chain on the state space \(\mathcal{S}\). For any integer \(h \geq 0\), \(x_{t-1}\in \mathcal{S}\) and subsets \(\mathcal{P} \subseteq \mathcal{S}^{t-1}\), \(\mathcal{F} \subseteq \mathcal{S}^{h+1}\) of state sequences of length \(t-1\) and \(h+1\) respectively, it holds that
One important implication of the Markov Property is that the distribution of a sample path, i.e., an event of the form \(\{X_0 = x_0, X_1 = x_1, \ldots, X_T = x_T\}\), simplifies considerably.
THEOREM (Distribution of a Sample Path) \(\idx{distribution of a sample path}\xdi\) For any \(x_0, x_1, \ldots, x_T \in \mathcal{S}\),
\(\sharp\)
Proof idea: We use the Multiplication Rule and the Markov Property.
Proof: We first apply the Multiplication Rule
with \(A_i = \{X_{i-1} = x_{i-1}\}\) and \(r = T+1\). That gives
Then we use the Markov Property to simplify each term in the product. \(\square\)
EXAMPLE: (Weather Model, continued) Going back to the weather model from a previous example, fix \(x_0 = \mathrm{Dry}\) and \(x_1,\ldots,x_t \in \S\). Then, by the Distribution of a Sample Path,
By assumption \(\P[X_0 = x_0] = 1\). Moreover, we have previously shown that
where \(z_{t-1} = \mathrm{Same}\) if \(x_t = x_{t-1}\) and \(z_{t-1} = \mathrm{Change}\) if \(x_t \neq x_{t-1}\).
Hence, using the distribution of \(Z_t\),
Let \(n_T = |\{0 < t \leq T : x_t = x_{t-1}\}|\) be the number of transitions without change. Then,
\(\lhd\)
It will be useful later on to observe that the Distribution of a Sample Path generalizes to
Based on the Distribution of a Sample Path, in order to specify the distribution of the process it suffices to specify
the initial distribution\(\idx{initial distribution}\xdi\) \(\mu_x := \P[X_0 = x]\) for all \(x\); and
the transition probabilities\(\idx{transition probability}\xdi\) \(\P[X_{t+1} = x\,|\,X_{t} = x']\) for all \(t\), \(x\), \(x'\).
7.2.2. Time-homogeneous case: transition matrix#
It is common to further assume that the process is time-homogeneous\(\idx{time-homogeneous process}\xdi\), which means that the transition probabilities do not depend on \(t\):
where the last equality is a definition. We can then collect the transition probabilities into a matrix.
DEFINITION (Transition Matrix) \(\idx{transition matrix}\xdi\) The matrix
is called the transition matrix of the chain. \(\natural\)
We also let \(\mu_{x} = \P[X_0 = x]\) and we think of \(\bmu = (\mu_{x})_{x \in \S}\) as a vector. The convention in Markov chain theory is to think of probability distributions such as \(\bmu\) as row vectors. We will see later why it simplifies the notation somewhat.
EXAMPLE: (Weather Model, continued) Going back to the weather model, let us number the states as follows: \(1 = \mathrm{Dry}\) and \(2 = \mathrm{Wet}\). Then the transition matrix is
\(\lhd\)
EXAMPLE: (Random Walk on the Petersen Graph, continued) Consider again the random walk on the Petersen graph \(G = (V,E)\). We number the vertices \(1, 2,\ldots, 10\). To compute the transition matrix, we list for each vertex its neighbors and put the value \(1/3\) in the corresponding columns. For instance, vertex \(1\) has neighbors \(2\), \(5\) and \(6\), so row \(1\) has \(1/3\) in columns \(2\), \(5\), and \(6\). And so on.
We get:
We have already encountered a matrix that encodes the neighbors of each vertex, the adjacency matrix. Here we can recover the transition matrix by multiplying the adjacency matrix by \(1/3\). \(\lhd\)
Transition matrices have a very special structure.
THEOREM (Transition Matrix is Stochastic) \(\idx{transition matrix is stochastic theorem}\xdi\) The transition matrix \(P\) is a stochastic matrix\(\idx{stochastic matrix}\xdi\), that is, all its entries are nonnegative and all its rows sum to one. \(\sharp\)
Proof: Indeed,
by the properties of the conditional probability. \(\square\)
In matrix form, the condition can be stated as \(P \mathbf{1} = \mathbf{1}\), where \(\mathbf{1}\) is an all-one vector of the appropriate size.
We have seen that any transition matrix is stochastic. Conversely, any stochastic matrix is the transition matrix of a Markov chain. That is, we can specify a Markov chain by choosing the number of states \(n\), an initial distribution over \(\mathcal{S} = [n]\) and a stochastic matrix \(P \in \mathbb{R}^{n\times n}\). Row \(i\) of \(P\) stipulates the probability distribution of the next state given that we are currently at state \(i\).
EXAMPLE: (Robot Vacuum) Suppose a robot vacuum roams around a large mansion with the following rooms: \(1=\mathrm{Study}\), \(2=\mathrm{Hall}\), \(3=\mathrm{Lounge}\), \(4=\mathrm{Library}\), \(5=\mathrm{Billiard\ Room}\), \(6=\mathrm{Dining\ Room}\), \(7=\mathrm{Conservatory}\), \(8=\mathrm{Ball\ Room}\), \(9=\mathrm{Kitchen}\).
Figure: A wrench (Credit: Made with Midjourney)

\(\bowtie\)
Once it is done cleaning a room, it moves to another one nearby according to the following stochastic matrix (check it is stochastic!):
Suppose the initial distribution \(\bmu\) is uniform over the state space and let \(X_t\) be the room the vacuum is in at iteration \(t\). Then \((X_t)_{t\geq 0}\) is a Markov chain. Unlike our previous examples, \(P\) is not symmetric. In particular, its rows sum to \(1\) but its columns do not. (Check it!) \(\lhd\)
When both rows and columns sum to \(1\), we say that \(P\) is doubly stochastic.
With the notation just introduced, the distribution of a sample path simplifies further to
This formula has a remarkable consequence. The marginal distribution of \(X_s\) is a matrix power of \(P\). As usual, we denote by \(P^s\) the \(s\)-th matrix power of \(P\). Recall also that \(\bmu\) is a row vector.
THEOREM (Time Marginals) \(\idx{time marginals theorem}\xdi\) For any \(s \geq 1\) and \(x_s \in \S\)
\(\sharp\)
Proof idea: The idea is to think of \(\P[X_s = x_s]\) as the time \(s\) marginal over all trajectories up to time \(s\) – quantities we know how to compute the probabilities of. Then we use the Distribution of a Sample Path and “pushe the sums in.” This is easier seen on a simple case. We do the case \(s=2\) first.
Summing over all trajectories up to time \(2\),
where we used the Distribution of a Sample Path.
Pushing the sum over \(x_1\) in, this becomes
where we recognized the definition of a matrix product – here \(P^2\). The result then follows.
Proof: For any \(s\), by definition of a marginal,
Using the Distribution of a Sample Path in the time-homogeneous case, this evaluates to
The sum can be simplified by pushing the individual sums as far into the summand as possible
where on the second line we recognized the innermost sum as a matrix product, then proceeded similarly. \(\square\)
The special case \(\bmu = \mathbf{e}_x^T\) gives that for any \(x, y \in [n]\)
EXAMPLE: (Weather Model, continued) Suppose day \(0\) is \(\mathrm{Dry}\), that is, the initial distribution is \(\bmu = (1,0)^T\). What is the probability that it is \(\mathrm{Wet}\) on day \(2\)? We apply the formula above to get \(\P[X_2 = 2] = \left(\bmu P^2\right)_{2}\). Note that
So the answer is \(3/8\). \(\lhd\)
It will be useful later on to observe that the Time Marginals Theorem generalizes to
for \(s \leq t\).
In the time-homogeneous case, an alternative way to represent a transition matrix is with a directed graph showing all possible transitions.
DEFINITION (Transition Graph) \(\idx{transition graph}\xdi\) Let \((X_t)_{t \geq 0}\) be a Markov chain over the state space \(\mathcal{S} = [n]\) with transition matrix \(P = (p_{i,j})_{i,j=1}^{n}\). The transition graph (or state transition diagram) of \((X_t)_{t \geq 0}\) is a directed graph with vertices \([n]\) and a directed edge from \(i\) to \(j\) if and only if \(p_{i,j} > 0\). We often associate a weight \(p_{i,j}\) to that edge. \(\natural\)
NUMERICAL CORNER: Returning to our Robot Vacuum Example, the transition graph of the chain can be obtained by thinking of \(P\) as the weighted adjacency matrix of the transition graph.
P_robot = np.array([[0, 0.8, 0, 0.2, 0, 0, 0, 0, 0],
[0.3, 0, 0.2, 0, 0, 0.5, 0, 0, 0],
[0, 0.6, 0, 0, 0, 0.4, 0, 0, 0],
[0.1, 0.1, 0, 0, 0.8, 0, 0, 0, 0],
[0, 0, 0, 0.25, 0, 0, 0.75, 0, 0],
[0, 0.15, 0.15, 0, 0, 0, 0, 0.35, 0.35],
[0, 0, 0, 0, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 0.3, 0.4, 0.2, 0, 0.1],
[0, 0, 0, 0, 0, 1, 0, 0, 0]])
We define a graph from its adjancency matrix. See networkx.from_numpy_array().
G_robot = nx.from_numpy_array(P_robot, create_using=nx.DiGraph)
Drawing edge weights on a directed graph in a readable fashion is not straighforward. We will not do this here.
Show code cell source
n_robot = P_robot.shape[0]
nx.draw_networkx(G_robot, pos=nx.circular_layout(G_robot),
labels={i: i+1 for i in range(n_robot)},
node_color='black', font_color='white',
connectionstyle='arc3, rad = 0.2')
plt.axis('off')
plt.show()
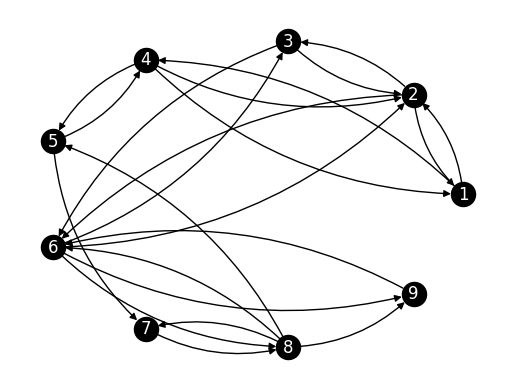
\(\unlhd\)
Once we have specified a transition matrix (and an initial distribution), we can simulate the corresponding Markov chain. This is useful to compute (approximately) probabilities of complex events through the law of large numbers. Here is some code to generate one sample path up to some given time \(T\). We assume that the state space is \([n]\). We use rng.choice to generate each transition.
def SamplePath(rng, mu, P, T):
n = mu.shape[0]
X = np.zeros(T+1)
for i in range(T+1):
if i == 0:
X[i] = rng.choice(a=np.arange(start=1,stop=n+1),p=mu)
else:
X[i] = rng.choice(a=np.arange(start=1,stop=n+1),p=P[int(X[i-1]-1),:])
return X
NUMERICAL CORNER: Let’s try with our Robot Vacuum. We take the initial distribution to be the uniform distribution.
seed = 535
rng = np.random.default_rng(seed)
mu = np.ones(n_robot) / n_robot
print(SamplePath(rng, mu, P_robot, 10))
[9. 6. 3. 6. 8. 6. 2. 1. 2. 6. 8.]
For example, we can use a simulation to approximate the expected number of times that room \(9\) is visited up to time \(10\). To do this, we run the simulation a large number of times (say \(1000\)) and count the average number of visits to \(9\).
z = 9
N_samples = 1000
visits_to_z = np.zeros(N_samples)
for i in range(N_samples):
visits_to_z[i] = np.count_nonzero(SamplePath(rng, mu, P_robot, 10) == z)
print(np.mean(visits_to_z))
1.193
\(\unlhd\)
CHAT & LEARN Markov Decision Processes (MDPs) are a framework for modeling decision making in situations where outcomes are partly random and partly under the control of a decision maker. Ask your favorite AI chatbot to explain the basic components of an MDP and how they relate to Markov chains. Discuss some applications of MDPs, such as in robotics or game theory. \(\ddagger\)
Self-assessment quiz (with help from Claude, Gemini, and ChatGPT)
1 Which of the following is true about the transition matrix \(P\) of a Markov chain?
a) All entries of \(P\) are non-negative, and all columns sum to one.
b) All entries of \(P\) are non-negative, and all rows sum to one.
c) All entries of \(P\) are non-negative, and both rows and columns sum to one.
d) All entries of \(P\) are non-negative, and either rows or columns sum to one, but not both.
2 What is the Markov Property?
a) The past and future are independent.
b) The past and future are independent given the present.
c) The present and future are independent given the past.
d) The past, present, and future are all independent.
3 Consider a Markov chain \((X_t)_{t \ge 0}\) on state space \(S\). Which of the following equations is a direct consequence of the Markov Property?
a) \(\mathbb{P}[X_{t+1} = x_{t+1} | X_t = x_t] = \mathbb{P}[X_{t+1} = x_{t+1}]\)
b) \(\mathbb{P}[X_{t+1} = x_{t+1} | X_t = x_t, X_{t-1} = x_{t-1}] = \mathbb{P}[X_{t+1} = x_{t+1} | X_t = x_t]\)
c) \(\mathbb{P}[X_{t+1} = x_{t+1} | X_t = x_t] = \mathbb{P}[X_{t+1} = x_{t+1} | X_0 = x_0]\)
d) \(\mathbb{P}[X_{t+1} = x_{t+1} | X_t = x_t, X_{t-1} = x_{t-1}] = \mathbb{P}[X_{t+1} = x_{t+1}]\)
4 Consider a Markov chain \((X_t)_{t\geq0}\) with transition matrix \(P = (p_{i,j})_{i,j}\) and initial distribution \(\mu\). Which of the following is true about the distribution of a sample path \((X_0, X_1, \ldots, X_T)\)?
a) \(\mathbb{P}[X_0 = x_0, X_1 = x_1, \ldots, X_T = x_T] = \mu_{x_0} \prod_{t=1}^T p_{x_{t-1},x_t}\)
b) \(\mathbb{P}[X_0 = x_0, X_1 = x_1, \ldots, X_T = x_T] = \mu_{x_0} \sum_{t=1}^T p_{x_{t-1},x_t}\)
c) \(\mathbb{P}[X_0 = x_0, X_1 = x_1, \ldots, X_T = x_T] = \prod_{t=0}^T \mu_{x_t}\)
d) \(\mathbb{P}[X_0 = x_0, X_1 = x_1, \ldots, X_T = x_T] = \sum_{t=0}^T \mu_{x_t}\)
5 In the random walk on the Petersen graph example, if the current state is vertex 9, what is the probability of transitioning to vertex 4 in the next step?
a) 0
b) 1/10
c) 1/3
d) 1
Answer for 1: b. Justification: The text states that “the transition matrix \(P\) is a stochastic matrix, that is, all its entries are nonnegative and all its rows sum to one.”
Answer for 2: b. Justification: The text summarizes the Markov Property as “the past and the future are independent given the present.”
Answer for 3: b. Justification: This is a direct statement of the Markov Property, where the future state \(X_{t+1}\) depends only on the present state \(X_t\) and not on the past state \(X_{t-1}\).
Answer for 4: a. Justification: The text states the Distribution of a Sample Path:
Answer for 5: c. Justification: In the Petersen graph, each vertex has 3 neighbors, and the random walk chooses one uniformly at random.