
\(\newcommand{\bmu}{\boldsymbol{\mu}}\) \(\newcommand{\bSigma}{\boldsymbol{\Sigma}}\) \(\newcommand{\bfbeta}{\boldsymbol{\beta}}\) \(\newcommand{\bflambda}{\boldsymbol{\lambda}}\) \(\newcommand{\bgamma}{\boldsymbol{\gamma}}\) \(\newcommand{\bsigma}{{\boldsymbol{\sigma}}}\) \(\newcommand{\bpi}{\boldsymbol{\pi}}\) \(\newcommand{\btheta}{{\boldsymbol{\theta}}}\) \(\newcommand{\bphi}{\boldsymbol{\phi}}\) \(\newcommand{\balpha}{\boldsymbol{\alpha}}\) \(\newcommand{\blambda}{\boldsymbol{\lambda}}\) \(\renewcommand{\P}{\mathbb{P}}\) \(\newcommand{\E}{\mathbb{E}}\) \(\newcommand{\indep}{\perp\!\!\!\perp} \newcommand{\bx}{\mathbf{x}}\) \(\newcommand{\bp}{\mathbf{p}}\) \(\renewcommand{\bx}{\mathbf{x}}\) \(\newcommand{\bX}{\mathbf{X}}\) \(\newcommand{\by}{\mathbf{y}}\) \(\newcommand{\bY}{\mathbf{Y}}\) \(\newcommand{\bz}{\mathbf{z}}\) \(\newcommand{\bZ}{\mathbf{Z}}\) \(\newcommand{\bw}{\mathbf{w}}\) \(\newcommand{\bW}{\mathbf{W}}\) \(\newcommand{\bv}{\mathbf{v}}\) \(\newcommand{\bV}{\mathbf{V}}\) \(\newcommand{\bfg}{\mathbf{g}}\) \(\newcommand{\bfh}{\mathbf{h}}\) \(\newcommand{\horz}{\rule[.5ex]{2.5ex}{0.5pt}}\) \(\renewcommand{\S}{\mathcal{S}}\) \(\newcommand{\X}{\mathcal{X}}\) \(\newcommand{\var}{\mathrm{Var}}\) \(\newcommand{\pa}{\mathrm{pa}}\) \(\newcommand{\Z}{\mathcal{Z}}\) \(\newcommand{\bh}{\mathbf{h}}\) \(\newcommand{\bb}{\mathbf{b}}\) \(\newcommand{\bc}{\mathbf{c}}\) \(\newcommand{\cE}{\mathcal{E}}\) \(\newcommand{\cP}{\mathcal{P}}\) \(\newcommand{\bbeta}{\boldsymbol{\beta}}\) \(\newcommand{\bLambda}{\boldsymbol{\Lambda}}\) \(\newcommand{\cov}{\mathrm{Cov}}\) \(\newcommand{\bfk}{\mathbf{k}}\) \(\newcommand{\idx}[1]{}\) \(\newcommand{\xdi}{}\)
7.5. Application: random walks on graphs and PageRank#
As we mentioned earlier in this chapter, a powerful way to extract information about the structure of a network is to analyze the behavior of a walker randomly “diffusing” on it.
7.5.1. Random walk on a graph#
We first specialize the theory of the previous section to random walks on graphs. We start with the case of digraphs. The undirected case leads to useful simplifications.
Directed case We first define a random walk on a digraph.
DEFINITION (Random Walk on a Digraph) \(\idx{random walk on a graph}\xdi\) Let \(G = (V,E)\) be a directed graph. If a vertex does not have an outgoing edge (i.e., an edge with it as its source), add a self-loop to it. A random walk on \(G\) is a time-homogeneous Markov chain \((X_t)_{t \geq 0}\) with state space \(\mathcal{S} = V\) and transition probabilities
where \(\delta^+(i)\) is the out-degree of \(i\), i.e., the number of outgoing edges and \(N^+(i) = \{j \in V:(i,j) \in E\}\). \(\natural\)
In words, at each step, we choose an outgoing edge from the current state uniformly at random. Choosing a self-loop (i.e., an edge of the form \((i,i)\)) means staying where we are.
Let \(G = (V,E)\) be a digraph with \(n = |V|\) vertices. Without loss of generality, we let the vertex set be \([n] = \{1,\ldots,n\}\). The adjacency matrix of \(G\) is denoted as \(A = (a_{i,j})_{i,j}\). We define the out-degree matrix \(D\) as the diagonal matrix with diagonal entries \(\delta^+(i)\), \(i=1,\ldots,n\). That is,
LEMMA (Transition Matrix in Terms of Adjacency) \(\idx{transition matrix in terms of adjacency}\xdi\) The transition matrix of random walk on \(G\) satisfying the conditions of the definition above is
\(\flat\)
Proof: The formula follows immediately from the definition. \(\square\)
We specialize irreducibility to the case of random walk on a digraph.
LEMMA (Irreducibility) \(\idx{irreducibility lemma}\xdi\) Let \(G = (V,E)\) be a digraph. Random walk on \(G\) is irreducible if and only if \(G\) is strongly connected. \(\flat\)
Proof: Simply note that the transition graph of the walk is \(G\) itself. We have seen previously that irreducibility is equivalent to the transition graph being strongly connected. \(\square\)
In the undirected case, more structure emerges as we detail next.
Undirected case Specializing the previous definitions and observations to undirected graphs, we get the following.
It will be convenient to allow self-loops, i.e., entry \(a_{i,i}\) of the adjacency matrix can be \(1\) for some \(i\).
DEFINITION (Random Walk on a Graph) \(\idx{random walk on a graph}\xdi\) Let \(G = (V,E)\) be a graph. If a vertex is isolated, add a self-loop to it. A random walk on \(G\) is a time-homogeneous Markov chain \((X_t)_{t \geq 0}\) with state space \(\mathcal{S} = V\) and transition probabilities
where \(\delta(i)\) is the degree of \(i\) and \(N(i) = \{j \in V: \{i,j\} \in E\}\). \(\natural\)
As we have seen previously, the transition matrix of random walk on \(G\) satisfying the conditions of the definition above is \(P = D^{-1} A\), where \(D = \mathrm{diag}(A \mathbf{1})\) is the degree matrix.
For instance, we have previously derived the transition matrix for random walk on the Petersen graph.
We specialize irreducibility to the case of random walk on a graph.
LEMMA (Irreducibility) \(\idx{irreducibility lemma}\xdi\) Let \(G = (V,E)\) be a graph. Random walk on \(G\) is irreducible if and only if \(G\) is connected. \(\flat\)
Proof: We only prove one direction. Suppose \(G\) is connected. Then between any two vertices \(i\) and \(j\) there is a sequence of vertices \(z_0 = i, z_1, \ldots, z_r = j\) such that \(\{z_{\ell-1},z_\ell\} \in E\) for all \(\ell = 1,\ldots,r\). In particular, \(a_{z_{\ell-1},z_\ell} > 0\) which implies \(p_{z_{\ell-1},z_\ell} > 0\). That proves irreducibility. \(\square\)
By the previous lemma and the Existence of a Stationary Distribution, provided \(G\) is connected, it has a unique stationary distribution. It turns out to be straightforward to compute it as we see in the next subsection.
Reversible chains A Markov chain is said to be reversible if it satisfies the detailed balance conditions.
DEFINITION (Reversibility) \(\idx{reversible}\xdi\) A transition matrix \(P = (p_{i,j})_{i,j=1}^n\) is reversible with respect to a probability distribution \(\bpi = (\pi_i)_{i=1}^n\) if it satisfies the so-called detailed balance conditions
\(\natural\)
The next theorem explains why this definition is useful to us.
THEOREM (Reversibility and Stationarity) \(\idx{reversibility and stationarity theorem}\xdi\) Let \(P = (p_{i,j})_{i,j=1}^n\) be a transition matrix reversible with respect to a probability distribution \(\bpi = (\pi_i)_{i=1}^n\). Then \(\bpi\) is a stationary distribution of \(P\). \(\sharp\)
Proof idea: Just check the definition.
Proof: For any \(j\), by the definition of reversibility,
where we used that \(P\) is stochastic in the last equality. \(\square\)
We return to random walk on a graph. We show that it is reversible and derive the stationary dsitribution.
THEOREM (Stationary Distribution on a Graph) \(\idx{stationary distribution on a graph}\xdi\) Let \(G = (V,E)\) be a graph. Assume further that \(G\) is connected. Then the unique stationary distribution of random walk on \(G\) is given by
\(\sharp\)
Proof idea: We prove this in two parts. We first argue that \(\bpi = (\pi_i)_{i \in V}\) is indeed a probability distribution. Then we show that the transition matrix \(P\) is reversible with respect to \(\bpi\).
Proof: We first show that \(\bpi = (\pi_v)_{v \in V}\) is a probability distribution. Its entries are non-negative by definition. Further
It remains to establish reversibility. For any \(i, j\), by definition,
Changing the roles of \(i\) and \(j\) gives the same expression since \(a_{j,i} = a_{i,j}\). \(\square\)
7.5.2. PageRank#
One is often interested in identifying central nodes in a network. Intuitively, they should correspond to entities (e.g., individuals or webpages depending on the network) that are particularly influential or authoritative. There are many ways of uncovering such nodes. Formally one defines a notion of node centrality\(\idx{node centrality}\xdi\), which ranks nodes by importance. Here we focus on one important such notion, PageRank. We will see that it is closely related to random walks on graphs.
A notion of centrality for directed graphs We start with the directed case.
Let \(G = (V,E)\) be a digraph on \(n\) vertices. We seek to associate a measure of importance to each vertex. We will denote this (row) vector by
where \(\mathrm{PR}\) stands for PageRank\(\idx{PageRank}\xdi\).
We posit that each vertex has a certain amount of influence associated to it and that it distributes that influence equally among the neighbors it points to. We seek a (row) vector \(\mathbf{z} = (z_1,\ldots,z_n)^T\) that satisfies an equation of the form
where \(\delta^+(j) = |N^+(j)|\) is the out-degree of \(j\) and \(N^-(i)\) is the set of vertices \(j\) with an edge \((j,i)\). Observe that we explicitly take into account the direction of the edges. We think of an edge \((j,i)\) as an indication that \(j\) values \(i\).
On the web for instance, a link towards a page indicates that the destination page has information of value. Quoting Wikipedia:
PageRank works by counting the number and quality of links to a page to determine a rough estimate of how important the website is. The underlying assumption is that more important websites are likely to receive more links from other websites.
On X (formerly known as Twitter), following an account is an indication that the latter is of interest.
We have already encountered this set of equations. Consider random walk on the directed graph \(G\) (where a self-loop is added to each vertex without an outgoing edge). That is, at every step, we pick an outgoing edge of the current state uniformly at random. Then the transition matrix is
where \(D\) is the diagonal matrix with the out-degrees on its diagonal.
A stationary distribution \(\bpi = (\pi_1,\ldots,\pi_n)^T\) is a row vector satisfying in this case
So \(\mathbf{z}\) is stationary distribution of random walk on \(G\).
If the graph \(G\) is strongly connected, we know that there is a unique stationary distribution by the Existence of a Stationary Distribution. In many real-world digraphs, however, that assumption is not satisfied. To ensure that a meaningful solution can still be found, we modify the walk slightly.
To make the walk irreducible, we add a small probability at each step of landing at a uniformly chosen node. This is sometimes referred to as teleporting. That is, we define the transition matrix
for some \(\alpha \in (0,1)\) known as the damping factor (or teleporting parameter). A typical choice is \(\alpha = 0.85\).
Note that \(\frac{1}{n} \mathbf{1} \mathbf{1}^T\) is a stochastic matrix. Indeed,
Hence, \(Q\) is a stochastic matrix (as a convex combination of stochastic matrices).
Moreover, \(Q\) is clearly irreducible since it is strictly positive. That is, for any \(x, y \in [n]\), one can reach \(y\) from \(x\) in a single step
This also holds for \(x = y\) so the chain is lazy.
Finally, we define \(\mathbf{PR}\) as the unique stationary distribution of \(Q = (q_{i,j})_{i,j=1}^n\), that is, the solution to
with \(\mathbf{PR} \geq 0\)
Quoting Wikipedia:
The formula uses a model of a random surfer who reaches their target site after several clicks, then switches to a random page. The PageRank value of a page reflects the chance that the random surfer will land on that page by clicking on a link. It can be understood as a Markov chain in which the states are pages, and the transitions are the links between pages – all of which are all equally probable.
Here is an implementation of the PageRank algorithm. We will need a function that takes as input an adjacency matrix \(A\) and returns the corresponding transition matrix \(P\). Some vertices have no outgoing links. To avoid dividing by \(0\), we add a self-loop to all vertices with out-degree \(0\). We numpy.fill_diagonal for this purpose. (The boolean values in sinks below automatically convert to 0.0 and 1.0 when used in the numerical matrix context. So this effectively adds self-loops only to sink nodes – nodes that had no outgoing edges now have a single outgoing edge pointing back to themselves.)
Also, because the adjacency matrix and the vector of out-degrees have different shapes, we turn out_deg into a column vector using numpy.newaxis to ensure that the division is done one column at a time. (There are many ways of doing this, but some are slower than others.)
def transition_from_adjacency(A):
n = A.shape[0]
sinks = (A @ np.ones(n)) == 0.
P = A.copy()
np.fill_diagonal(P, sinks)
out_deg = P @ np.ones(n)
P = P / out_deg[:, np.newaxis]
return P
The following function adds the damping factor. Here mu will be the uniform distribution. It gets added (after scaling by 1-alpha) one row at a time to P (again after scaling by alpha). This time we do not need to reshape mu as the sum is done one row at a time.
def add_damping(P, alpha, mu):
Q = alpha * P + (1-alpha) * mu
return Q
When computing PageRank, we multiply from the left.
def pagerank(A, alpha=0.85, max_iter=100):
n = A.shape[0]
mu = np.ones(n)/n
P = transition_from_adjacency(A)
Q = add_damping(P, alpha, mu)
v = mu
for _ in range(max_iter):
v = v @ Q
return v
NUMERICAL CORNER: Let’s try a star with edges pointing out. Along the way, we check that our functions work how we expect them to.
n = 8
G_outstar = nx.DiGraph()
for i in range(1,n):
G_outstar.add_edge(0,i)
nx.draw_networkx(G_outstar, labels={i: i+1 for i in range(n)},
node_color='black', font_color='white')
plt.axis('off')
plt.show()
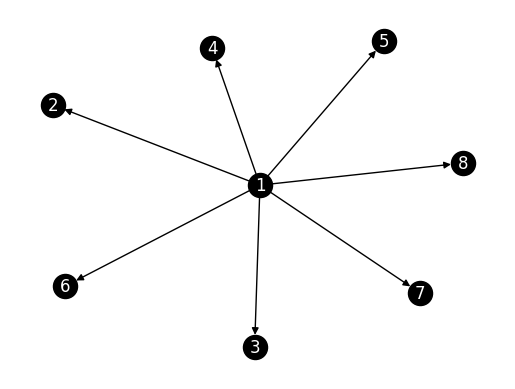
A_outstar = nx.adjacency_matrix(G_outstar).toarray()
print(A_outstar)
[[0 1 1 1 1 1 1 1]
[0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]]
We compute the matrices \(P\) and \(Q\). We use numpy.set_printoptions to condense the output.
P_outstar = transition_from_adjacency(A_outstar)
np.set_printoptions(formatter={'float': '{: 0.3f}'.format})
print(P_outstar)
[[ 0.000 0.143 0.143 0.143 0.143 0.143 0.143 0.143]
[ 0.000 1.000 0.000 0.000 0.000 0.000 0.000 0.000]
[ 0.000 0.000 1.000 0.000 0.000 0.000 0.000 0.000]
[ 0.000 0.000 0.000 1.000 0.000 0.000 0.000 0.000]
[ 0.000 0.000 0.000 0.000 1.000 0.000 0.000 0.000]
[ 0.000 0.000 0.000 0.000 0.000 1.000 0.000 0.000]
[ 0.000 0.000 0.000 0.000 0.000 0.000 1.000 0.000]
[ 0.000 0.000 0.000 0.000 0.000 0.000 0.000 1.000]]
alpha = 0.85
mu = np.ones(n)/n
Q_outstar = add_damping(P_outstar, alpha, mu)
print(Q_outstar)
[[ 0.019 0.140 0.140 0.140 0.140 0.140 0.140 0.140]
[ 0.019 0.869 0.019 0.019 0.019 0.019 0.019 0.019]
[ 0.019 0.019 0.869 0.019 0.019 0.019 0.019 0.019]
[ 0.019 0.019 0.019 0.869 0.019 0.019 0.019 0.019]
[ 0.019 0.019 0.019 0.019 0.869 0.019 0.019 0.019]
[ 0.019 0.019 0.019 0.019 0.019 0.869 0.019 0.019]
[ 0.019 0.019 0.019 0.019 0.019 0.019 0.869 0.019]
[ 0.019 0.019 0.019 0.019 0.019 0.019 0.019 0.869]]
While it is tempting to guess that \(1\) is the most central node of the network, no edge actually points to it. In this case, the center of the star has a low PageRank value.
print(pagerank(A_outstar))
[ 0.019 0.140 0.140 0.140 0.140 0.140 0.140 0.140]
We then try a star with edges pointing in.
n = 8
G_instar = nx.DiGraph()
G_instar.add_node(0)
for i in range(1,n):
G_instar.add_edge(i,0)
nx.draw_networkx(G_instar, labels={i: i+1 for i in range(n)},
node_color='black', font_color='white')
plt.axis('off')
plt.show()
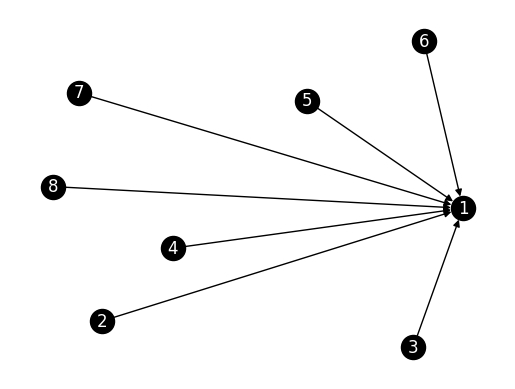
A_instar = nx.adjacency_matrix(G_instar).toarray()
print(A_instar)
[[0 0 0 0 0 0 0 0]
[1 0 0 0 0 0 0 0]
[1 0 0 0 0 0 0 0]
[1 0 0 0 0 0 0 0]
[1 0 0 0 0 0 0 0]
[1 0 0 0 0 0 0 0]
[1 0 0 0 0 0 0 0]
[1 0 0 0 0 0 0 0]]
P_instar = transition_from_adjacency(A_instar)
print(P_instar)
[[ 1.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000]
[ 1.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000]
[ 1.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000]
[ 1.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000]
[ 1.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000]
[ 1.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000]
[ 1.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000]
[ 1.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000]]
Q_instar = add_damping(P_instar, alpha, mu)
print(Q_instar)
[[ 0.869 0.019 0.019 0.019 0.019 0.019 0.019 0.019]
[ 0.869 0.019 0.019 0.019 0.019 0.019 0.019 0.019]
[ 0.869 0.019 0.019 0.019 0.019 0.019 0.019 0.019]
[ 0.869 0.019 0.019 0.019 0.019 0.019 0.019 0.019]
[ 0.869 0.019 0.019 0.019 0.019 0.019 0.019 0.019]
[ 0.869 0.019 0.019 0.019 0.019 0.019 0.019 0.019]
[ 0.869 0.019 0.019 0.019 0.019 0.019 0.019 0.019]
[ 0.869 0.019 0.019 0.019 0.019 0.019 0.019 0.019]]
In this case, the center of the star does indeed have a high PageRank value.
print(pagerank(A_instar))
[ 0.869 0.019 0.019 0.019 0.019 0.019 0.019 0.019]
\(\unlhd\)
A notion of centrality for undirected graphs We can apply PageRank\(\idx{PageRank}\xdi\) in the undirected case as well.
Consider random walk on the undirected graph \(G\). That is, at every step, we pick a neighbor of the current state uniformly at random. If needed, add a self-loop to any isolated vertex. Then the transition matrix is
where \(D\) is the degree matrix and \(A\) is the adjacency matrix. A stationary distribution \(\bpi = (\pi_1,\ldots,\pi_n)^T\) is a row vector satisfying in this case
We already know the solution to this system of equations. In the connected case without damping, the unique stationary distribution of random walk on \(G\) is given by
In words, the centrality of a node is directly proportional to its degree, i.e., how many neighbors it has. Up to the scaling factor, this is known as degree centrality\(\idx{degree centrality}\xdi\).
For a general undirected graph that may not be connected, we can use a damping factor to enforce irreducibility. We add a small probability at each step of landing at a uniformly chosen node. That is, we define the transition matrix
for some \(\alpha \in (0,1)\) known as the damping factor. We define the PageRank vector \(\mathbf{PR}\) as the unique stationary distribution of \(Q = (q_{i,j})_{i,j=1}^n\), that is, the solution to
with \(\mathbf{PR} \geq 0\)
NUMERICAL CORNER: We revisit the star example in the undirected case.
n = 8
G_star = nx.Graph()
for i in range(1,n):
G_star.add_edge(0,i)
nx.draw_networkx(G_star, labels={i: i+1 for i in range(n)},
node_color='black', font_color='white')
plt.axis('off')
plt.show()
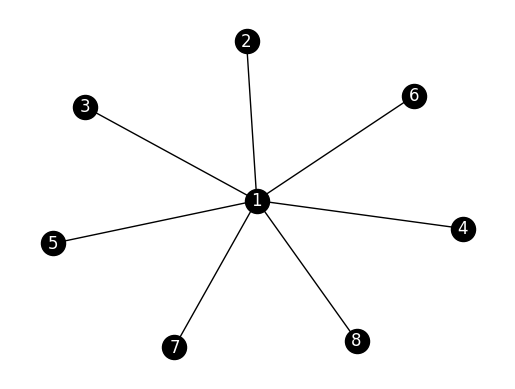
We first compute the PageRank vector without damping. Here the random walk is periodic (Why?) so power iteration may fail (Try it!). Instead, we use a small amount of damping and increase the number of iterations.
A_star = nx.adjacency_matrix(G_star).toarray()
print(A_star)
[[0 1 1 1 1 1 1 1]
[1 0 0 0 0 0 0 0]
[1 0 0 0 0 0 0 0]
[1 0 0 0 0 0 0 0]
[1 0 0 0 0 0 0 0]
[1 0 0 0 0 0 0 0]
[1 0 0 0 0 0 0 0]
[1 0 0 0 0 0 0 0]]
print(pagerank(A_star, max_iter=10000, alpha=0.999))
[ 0.500 0.071 0.071 0.071 0.071 0.071 0.071 0.071]
The PageRank value for the center node is indeed roughly \(7\) times larger than the other ones, as can be expected from the ratio of their degrees.
We try again with more damping. This time the ratio of PageRank values is not quite the same as the ratio of degrees, but the center node continues to have a higher value than the other nodes.
print(pagerank(A_star))
[ 0.470 0.076 0.076 0.076 0.076 0.076 0.076 0.076]
\(\unlhd\)
CHAT & LEARN There are many other centrality measures besides PageRank, such as betweenness centrality, closeness centrality, and eigenvector centrality. Ask your favorite AI chatbot to explain these measures and discuss their similarities and differences with PageRank. \(\ddagger\)
7.5.3. Personalized PageRank#
We return to MathWorld dataset. Recall that each page of MathWorld concerns a particular mathematical concept. In a section entitled “SEE ALSO”, other related mathematical concepts are listed with a link to their MathWorld page. Our goal is to identify “central” vertices in the resulting graph.
Figure: Platonic solids (Credit: Made with Midjourney)

\(\bowtie\)
NUMERICAL CORNER: We load the dataset again.
data_edges = pd.read_csv('mathworld-adjacency.csv')
data_edges.head()
| from | to | |
|---|---|---|
| 0 | 0 | 2 |
| 1 | 1 | 47 |
| 2 | 1 | 404 |
| 3 | 1 | 2721 |
| 4 | 2 | 0 |
The second file contains the titles of the pages.
data_titles = pd.read_csv('mathworld-titles.csv')
data_titles.head()
| title | |
|---|---|
| 0 | Alexander's Horned Sphere |
| 1 | Exotic Sphere |
| 2 | Antoine's Horned Sphere |
| 3 | Flat |
| 4 | Poincaré Manifold |
We construct the graph by adding the edges one by one. We first convert df_edges into a NumPy array.
edgelist = data_edges[['from','to']].to_numpy()
print(edgelist)
[[ 0 2]
[ 1 47]
[ 1 404]
...
[12361 12306]
[12361 12310]
[12361 12360]]
n = 12362
G_mw = nx.empty_graph(n, create_using=nx.DiGraph)
for i in range(edgelist.shape[0]):
G_mw.add_edge(edgelist[i,0], edgelist[i,1])
To apply PageRank, we construct the adjacency matric of the graph. We also define a vector of title pages.
A_mw = nx.adjacency_matrix(G_mw).toarray()
titles_mw = data_titles['title'].to_numpy()
pr_mw = pagerank(A_mw)
We use numpy.argsort to identify the pages with highest scores. We apply it to -pr_mw to sort from the highest to lowest value.
top_pages = np.argsort(-pr_mw)
The top 25 topics are:
print(titles_mw[top_pages[:25]])
['Sphere' 'Circle' 'Prime Number' 'Aleksandrov-Čech Cohomology'
'Centroid Hexagon' 'Group' 'Fourier Transform' 'Tree' 'Splitting Field'
'Archimedean Solid' 'Normal Distribution' 'Integer Sequence Primes'
'Perimeter Polynomial' 'Polygon' 'Finite Group' 'Large Number'
'Riemann Zeta Function' 'Chebyshev Approximation Formula' 'Vector' 'Ring'
'Fibonacci Number' 'Conic Section' 'Fourier Series' 'Derivative'
'Gamma Function']
We indeed get a list of central concepts in mathematics – including several we have encountered previously such as Normal Distribution, Tree, Vector or Derivative.
\(\unlhd\)
There is a variant of PageRank, referred to as Personalized PageRank (PPR)\(\idx{Personalized PageRank}\xdi\), which aims to tailor the outcome to specific interests. This is accomplished from a simple change to the algorithm. When teleporting, rather than jumping to a uniformly random page, we instead jump to an arbitrary distribution which is meant to capture some specific interests. In the context of the web for instance, this distribution might be uniform over someone’s bookmarks.
We adapt pagerank as follows:
def ppr(A, mu, alpha=0.85, max_iter=100):
n = A.shape[0]
P = transition_from_adjacency(A)
Q = add_damping(P, alpha, mu)
v = mu
for _ in range(max_iter):
v = v @ Q
return v
NUMERICAL CORNER: To test PPR, consider the distribution concentrated on a single topic Normal Distribution. This is topic number 1270.
print(np.argwhere(titles_mw == 'Normal Distribution')[0][0])
1270
mu = np.zeros(n)
mu[1270] = 1
We now run PPR and list the top 25 pages.
ppr_mw = ppr(A_mw, mu)
top_pers_pages = np.argsort(-ppr_mw)
The top 25 topics are:
print(titles_mw[top_pers_pages[:25]])
['Normal Distribution' 'Pearson System' 'Logit Transformation' 'z-Score'
'Erf' 'Central Limit Theorem' 'Bivariate Normal Distribution'
'Normal Ratio Distribution' 'Normal Sum Distribution'
'Normal Distribution Function' 'Gaussian Function'
'Standard Normal Distribution' 'Normal Product Distribution'
'Binomial Distribution' 'Tetrachoric Function' 'Ratio Distribution'
'Kolmogorov-Smirnov Test' 'Box-Muller Transformation' 'Galton Board'
'Fisher-Behrens Problem' 'Erfc' 'Normal Difference Distribution'
'Half-Normal Distribution' 'Inverse Gaussian Distribution'
'Error Function Distribution']
This indeed returns various statistical concepts, particularly related to the normal dsitribution.
\(\unlhd\)
CHAT & LEARN The PageRank algorithm has been adapted for various applications beyond web search, such as ranking scientific papers, analyzing social networks, and even ranking sports teams [Gle]. Ask your favorite AI chatbot to discuss some of these applications and how the PageRank algorithm is modified for each case. \(\ddagger\)
Self-assessment quiz (with help from Claude, Gemini, and ChatGPT)
1 Consider a random walk on the following graph:
G = nx.Graph()
G.add_edges_from([(0, 1), (1, 2), (2, 0)])
What is the transition matrix for this random walk?
a)
b)
c)
d)
2 In a random walk on a directed graph, the transition probability from vertex \(i\) to vertex \(j\) is given by:
a) \(p_{i,j} = \frac{1}{\delta^-(j)}\) for all \(j \in N^-(i)\)
b) \(p_{i,j} = \frac{1}{\delta^+(j)}\) for all \(j \in N^+(i)\)
c) \(p_{i,j} = \frac{1}{\delta^-(i)}\) for all \(j \in N^-(i)\)
d) \(p_{i,j} = \frac{1}{\delta^+(i)}\) for all \(j \in N^+(i)\)
3 The transition matrix \(P\) of a random walk on a directed graph can be expressed in terms of the adjacency matrix \(A\) as:
a) \(P = AD^{-1}\)
b) \(P = A^TD^{-1}\)
c) \(P = D^{-1}A\)
d) \(P = D^{-1}A^T\)
4 In a random walk on an undirected graph, the stationary distribution \(\boldsymbol{\pi}\) satisfies:
a) \(\pi_i = \frac{\delta^+(i)}{\sum_{j \in V} \delta^+(j)}\) for all \(i \in V\)
b) \(\pi_i = \frac{1}{\delta(i)}\) for all \(i \in V\)
c) \(\pi_i = \frac{1}{|V|}\) for all \(i \in V\)
d) \(\pi_i = \frac{\delta(i)}{\sum_{j \in V} \delta(j)}\) for all \(i \in V\)
5 Personalized PageRank differs from standard PageRank in that:
a) It considers the user’s browsing history
b) It jumps to a non-uniform distribution when teleporting
c) It uses a different damping factor
d) It only considers a subset of the graph
Answer for 1: b. Justification: Each node has a degree of 2, and the probability of transitioning to each neighbor is 1/2.
Answer for 2: d. Justification: The text states, “In words, at each step, we choose an outgoing edge from the current state uniformly at random,” which corresponds to the transition probability \(p_{i,j} = \frac{1}{\delta^+(i)}\) for all \(j \in N^+(i)\), where \(\delta^+(i)\) is the out-degree of vertex \(i\) and \(N^+(i)\) is the set of vertices with an edge from \(i\).
Answer for 3: c. Justification: The text states, “The transition matrix of random walk on \(G\) satisfying the conditions of the definition above is \(P = D^{-1}A\), where \(D\) is the out-degree matrix.”
Answer for 4: d. Justification: The text states, “In the connected case without damping, the unique stationary distribution of random walk on \(G\) is given by \(\pi_i = \frac{\delta(i)}{\sum_{i \in V} \delta(i)}, \forall i \in V\).”
Answer for 5: b. Justification: The text states, “When teleporting, rather than jumping to a uniformly random page, we instead jump to an arbitrary distribution \(\boldsymbol{\mu}\) which is meant to capture some specific interests.”